GBase 8a 支持开窗子句rows和range, 本文介绍开窗子句的使用方法。
目录导航
参考
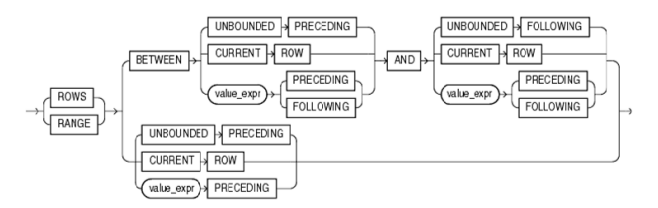
语法
- rows :指行,包含边界行
- range :数值范围,包含边界值
- Unbounded :是无边界
- Preceding :向上,减去,提前
- Following :向下,加上,延后
- Current row :当前行
使用说明
- _t_gbase_new_window_function_support 参数为控制支持windowing_clause 子句的参数,参数值默认为 0,不支持 windowing_clause 子句,设置为 1 时支持 windowing_clause 子句。set _t_gbase_new_window_function_support=1
- 不支持 windowing_clause 子句情况下,开窗方式是固定的,范围是:Range between unbounded preceding and current row
- Partition 子句为空,则不分组,即说明全部数据为一组;order by 子句为空,则每个分组中的所有数据不排序,即一个分组就是一个“子窗口”。
- between bound1 and bound2。
- bound1 定义窗口的起始位置,
- bound2 定义窗口的结束位置。
- 单独一个 bound 时,为起始位置的定义,结束位置默认为 current row,如:select a,b,c,sum(c)over(partition by a order by b range 2 preceding) as 'sum(c)' from t;
- unbounded preceding 指明起始位置,即当前分组中的行首,不能出现在 bound2 中。
- unbounded following 指明结束位置,即当前分组中的行尾,不能出现在 bound1 中。
- current row 指明起始或结束位置为当前行。
- 在如下情况时,order by 关键字后可以有多个表达式:
- Range between unbounded preceding and current row
- Range between unbounded preceding and unbounded following
- Range between current row and current row
- Range between current row and unbounded following
- value_expr preceding | value_expr following
- 起始位置为 value_expr following 时,则结束位置应为 value_expr following;
- 结束位置为 value_expr preceding 时,则起始位置应为 value_expr preceding。
- rows 关键字后接 value_expr 时,不支持 interval 子句
- value_expr 为 num 时,标识了行的偏移量,为数值常量,正整数(四舍五入)。不可为负数、数值函数、表列。
- range 关键字后接 value_expr 时支持 interval 子句,且 order by 后只能有一个表达式:
- value_expr 为 num 时,order by 后的表达式只能为数值或日期(时间)类型;
- value_expr 为 interval 子句时,order by 后的表达式只能为日期(时间)类型;
- value_expr 为 num 时,标识了行的偏移量,为数值常量,正整数(四舍五入)。不可为负数、数值函数、表列。
- range 关键字,order by 后接唯一表达式用于计算窗口范围时:
- 排序存在 null 值且在行首时,除非 unbounded preceding,该行不计入窗口范围;
- 排序存在 null 值且在行尾时,除非 unbounded following,该行不计入窗口范围;
- 当前行为 null 值,除非 unbounded preceding/following,窗口范围仅为该行。
- 日期(时间)类型的支持范围:date、datetime 和 timestamp。
数据
gbase> create table t2(id int, type int, val int);
Query OK, 0 rows affected (Elapsed: 00:00:00.14)
gbase> insert into t2 values(1,1,111),(2,1,122),(3,1,133),(4,2,222),(5,2,233),(6,2,244),(7,3,333);
Query OK, 7 rows affected (Elapsed: 00:00:00.11)
Records: 7 Duplicates: 0 Warnings: 0
gbase> desc t2;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| type | int(11) | YES | | NULL | |
| val | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
3 rows in set (Elapsed: 00:00:00.00)
gbase> select * from t2 order by type,val;
+------+------+------+
| id | type | val |
+------+------+------+
| 1 | 1 | 111 |
| 2 | 1 | 122 |
| 3 | 1 | 133 |
| 4 | 2 | 222 |
| 5 | 2 | 233 |
| 6 | 2 | 244 |
| 7 | 3 | 333 |
+------+------+------+
7 rows in set (Elapsed: 00:00:00.02)
ROWS的例子
如下以SUM OVER为例子介绍。
整体汇总值
gbase> select sum(val) v from t2;
+------+
| v |
+------+
| 1398 |
+------+
1 row in set (Elapsed: 00:00:00.03)
移动汇总值
数据按照类型,数字排序,计算之前的汇总值。
移动汇总可以参考: GBase 8a OLAP函数移动平均值AVG,移动汇总SUM,移动计数count over等使用样例
gbase> select t2.*,sum(val) over(order by type,val) v from t2;
+------+------+------+------+
| id | type | val | v |
+------+------+------+------+
| 1 | 1 | 111 | 111 |
| 2 | 1 | 122 | 233 |
| 3 | 1 | 133 | 366 |
| 4 | 2 | 222 | 588 |
| 5 | 2 | 233 | 821 |
| 6 | 2 | 244 | 1065 |
| 7 | 3 | 333 | 1398 |
+------+------+------+------+
7 rows in set (Elapsed: 00:00:00.03)
按类型分区计算移动汇总值
按照类型不同,各自计算移动汇总值。每个类型各自计算。
移动汇总可以参考: GBase 8a OLAP函数移动平均值AVG,移动汇总SUM,移动计数count over等使用样例
gbase> select t2.*,sum(val) over(partition by type order by type,val) v from t2;
+------+------+------+------+
| id | type | val | v |
+------+------+------+------+
| 4 | 2 | 222 | 222 |
| 5 | 2 | 233 | 455 |
| 6 | 2 | 244 | 699 |
| 1 | 1 | 111 | 111 |
| 2 | 1 | 122 | 233 |
| 3 | 1 | 133 | 366 |
| 7 | 3 | 333 | 333 |
+------+------+------+------+
7 rows in set (Elapsed: 00:00:00.05)指定rows的整体移动汇总值current row
先看看不分区的整体移动汇总值的情况。我们例子里指定汇总前1个数值和当前值,而不是默认的移动汇总值的,所有前面的。如下贴了2个结果,方便对比。
可以看到普通移动汇总,数值一直在累加之前的,而指定了rows的,只汇总了指定范围内的。
| select t2.*,sum(val) over(order by type,val) v from t2; | select t2.*,sum(val) over(order by type,val rows between 1 preceding and current row) v from t2; |
+------+------+------+------+ | +------+------+------+------+ |
指定rows的整体移动汇总值following
本例指定前1个和后1个,共3个(如果有的话)的移动汇总值。
gbase> select t2.*,sum(val) over(order by type,val rows between 1 preceding and 1 following) v from t2;
+------+------+------+------+
| id | type | val | v |
+------+------+------+------+
| 1 | 1 | 111 | 233 |
| 2 | 1 | 122 | 366 |
| 3 | 1 | 133 | 477 |
| 4 | 2 | 222 | 588 |
| 5 | 2 | 233 | 699 |
| 6 | 2 | 244 | 810 |
| 7 | 3 | 333 | 577 |
+------+------+------+------+
7 rows in set (Elapsed: 00:00:00.02)指定rows的分区移动汇总值
| select t2.*,sum(val) over(partition by type order by type,val) v from t2; | select t2.*,sum(val) over(partition by type order by type,val rows between 1 preceding and current row) v from t2; |
+------+------+------+------+ | +------+------+------+------+ |
RANGE的例子
同样以SUM OVER为例子,分别计算前面差距小于100的;前面差距小于100和后面差距小于100的。
| gbase> select t2.*,sum(val) over(order by type,val) v from t2; | select t2.*,sum(val) over(order by val range between 100 preceding and 1 following) v from t2; | select t2.*,sum(val) over(order by val range between 100 preceding and 100 following) v from t2; |
+------+------+------+------+ | +------+------+------+------+ | +------+------+------+------+ |
时间类型的RANGE例子
换个数据表
gbase> select * from t3;
+------+--------+------------+
| id | name | birth |
+------+--------+------------+
| 1 | 张三 | 1960-01-01 |
| 2 | 李四 | 1970-01-01 |
| 3 | 王五 | 1980-01-01 |
| 4 | 赵六 | 1990-01-01 |
+------+--------+------------+
4 rows in set (Elapsed: 00:00:00.01)
分别计算:向前无边界,向后5、10、20年生日差距的的数据。
gbase> select t3.*,sum(id)over(order by birth range between unbounded preceding and interval 5 year following) v from t3;
+------+--------+------------+------+
| id | name | birth | v |
+------+--------+------------+------+
| 1 | 张三 | 1960-01-01 | 1 |
| 2 | 李四 | 1970-01-01 | 3 |
| 3 | 王五 | 1980-01-01 | 6 |
| 4 | 赵六 | 1990-01-01 | 10 |
+------+--------+------------+------+
4 rows in set (Elapsed: 00:00:00.02)
gbase> select t3.*,sum(id)over(order by birth range between unbounded preceding and interval 10 year following) v from t3;
+------+--------+------------+------+
| id | name | birth | v |
+------+--------+------------+------+
| 1 | 张三 | 1960-01-01 | 3 |
| 2 | 李四 | 1970-01-01 | 6 |
| 3 | 王五 | 1980-01-01 | 10 |
| 4 | 赵六 | 1990-01-01 | 10 |
+------+--------+------------+------+
4 rows in set (Elapsed: 00:00:00.02)
gbase> select t3.*,sum(id)over(order by birth range between unbounded preceding and interval 20 year following) v from t3;
+------+--------+------------+------+
| id | name | birth | v |
+------+--------+------------+------+
| 1 | 张三 | 1960-01-01 | 6 |
| 2 | 李四 | 1970-01-01 | 10 |
| 3 | 王五 | 1980-01-01 | 10 |
| 4 | 赵六 | 1990-01-01 | 10 |
+------+--------+------------+------+
4 rows in set (Elapsed: 00:00:00.05)