采集并汇总GBase 8a,oceanbase,tidb,polardb-O,gaussdb200,clickhouse,flink,spark等数据库的整体架构图和对应说明,方便从整体上看数据库之间的差异。
新搜集到的数据库材料,我放到了最前面。
目录导航
星环TDH
来源: https://www.transwarp.cn/transwarp/product-TDH.html?categoryId=18
核心: Inceptor 基于Hadoop和Spark技术平台打造

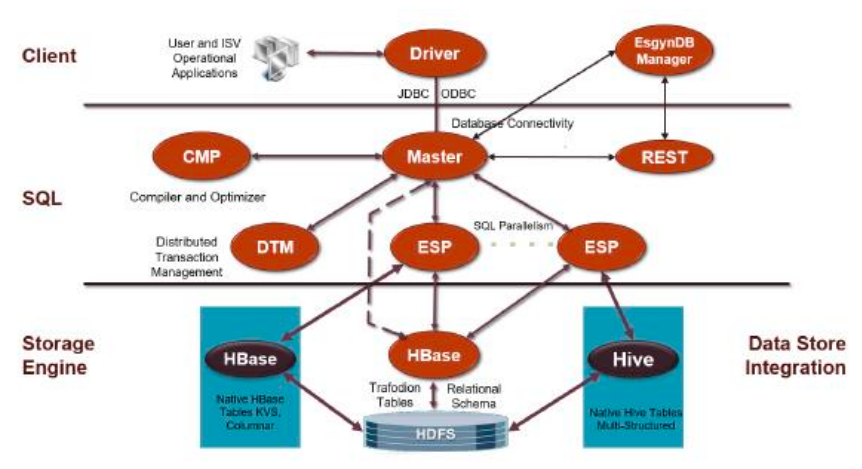
易鲸捷 EsgynDB
来源:http://www.esgyn.cn/wp-content/uploads/avatar_images/EsgynDB%E5%8F%82%E8%80%83%E6%9E%B6%E6%9E%84.pdf
https://www.modb.pro/wiki/43
核心:基于Apache Trafodion, 2021年4月改名叫 attic

中兴通讯GoldenDB
来源:https://www.zte.com.cn/china/products/202003190856/202003190858/201707311038
神通数据库MPP集群
来源:http://www.shentongdata.com/index.php/product/view-103
巨杉Sequoiadb
来源:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1558957225-edition_id-500
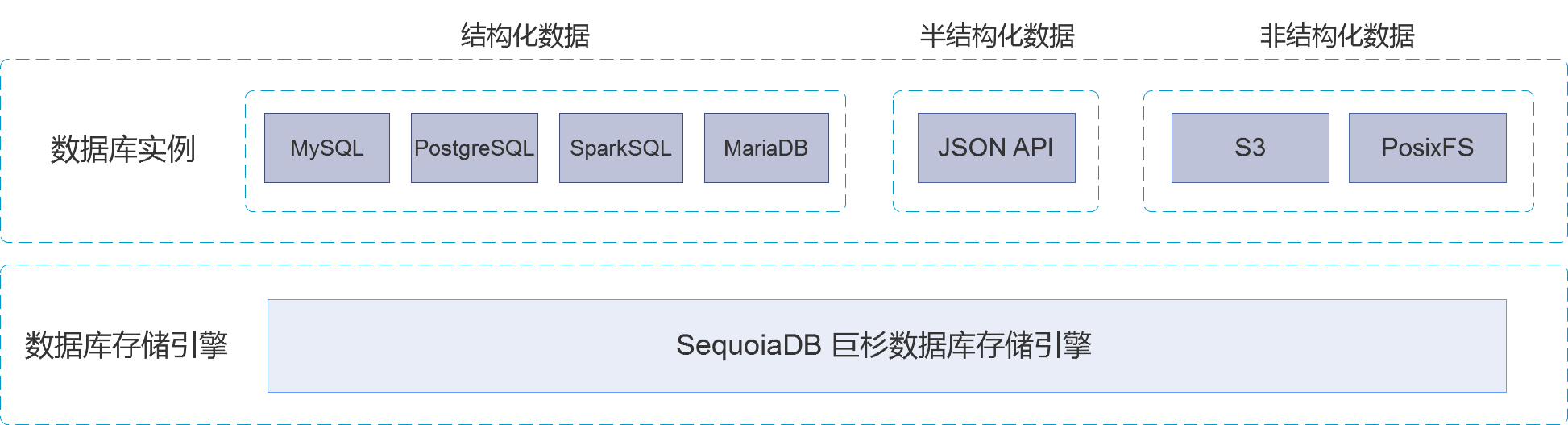
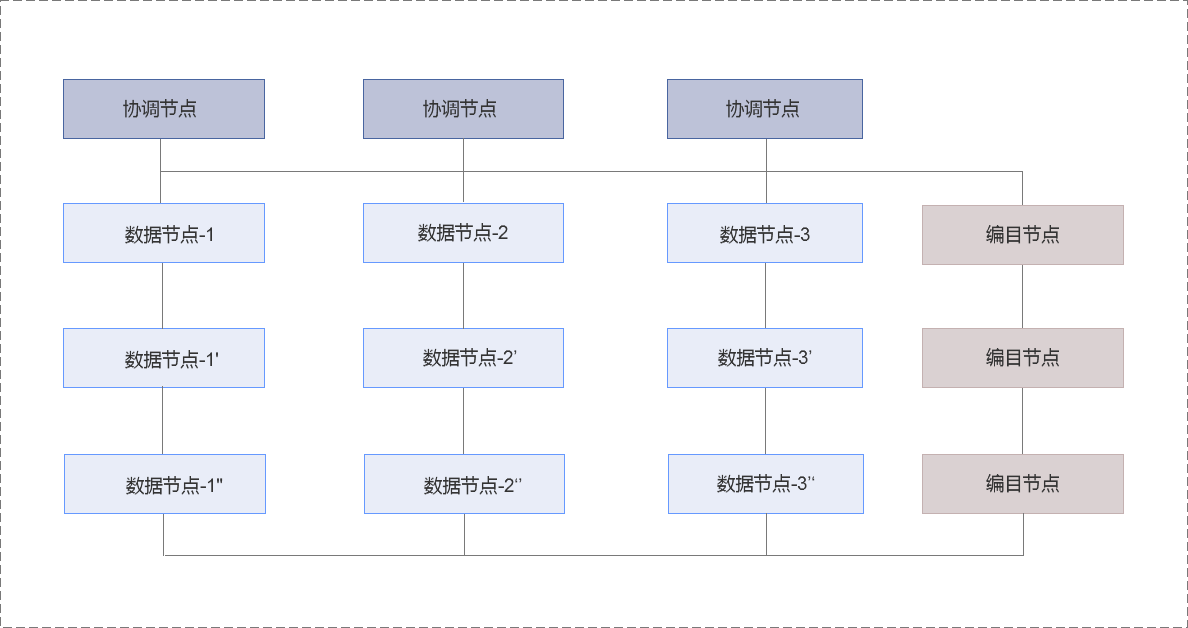
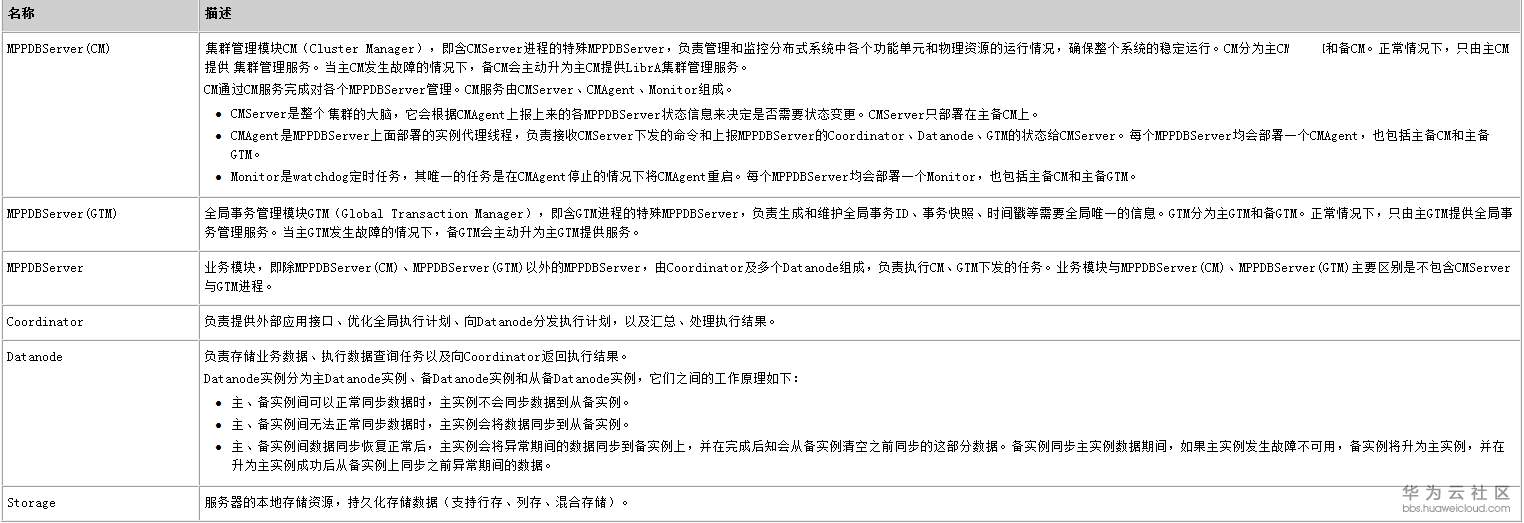
协调节点
协调节点不存储任何用户数据。作为外部访问的接入与请求分发节点,协调节点将用户请求分发至相应的数据节点,最终合并数据节点的结果应答对外进行响应。
编目节点
编目节点主要存储系统的节点信息、用户信息、分区信息以及对象定义等元数据。在特定操作下,协调节点与数据节点均会向编目节点请求元数据信息,以感知数据的分布规律和校验请求的正确性。
数据节点
数据节点为用户数据的物理存储节点,海量数据通过分片切分的方式被分散至不同的数据节点。在关系型与 JSON 数据库实例中,每一条记录会被完整地存放在其中一个或多个数据节点中;而在对象存储实例中,每一个文件将会依据数据页大小被拆分成多个数据块,并被分散至不同的数据节点进行存放。
阿里云 AnalyticDB PostgreSQL
来源:https://www.aliyun.com/product/gpdb
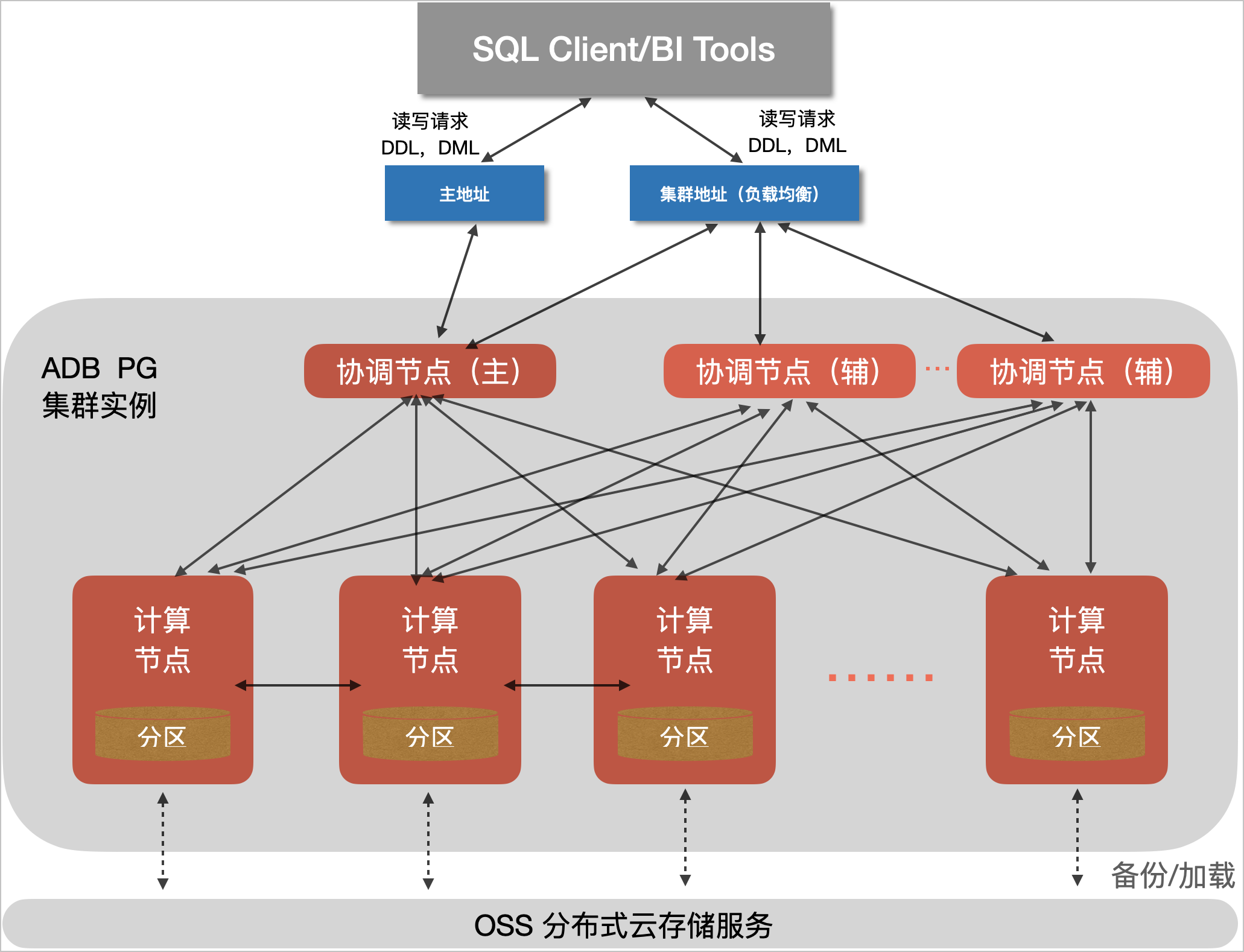
AnalyticDB PostgreSQL版采用MPP架构,实例由多个计算节点组成,存储磁盘类型支持高效云盘和ESSD云盘,计算和存储分离,可以独立增加节点或扩容,且保持查询响应时间不变。集群实例包括的组件有 :
- 协调节点(Master Node)。
- 接收请求,制定分布式执行计划。
- 计算节点(Compute Groups)。
- 全并行分析计算
- 数据分区双副本存储
- 定期自动备份至OSS
区别于Greenplum, 2021年2月8日,AnalyticDB PostgreSQL版正式开放多Master的能力,支持通过水平扩展协调节点(Master Node)来突破原架构单Master的限制,在计算节点不存在瓶颈的情况下,系统连接数及读写能力可以随着Master节点数增加实现线性扩展,从而进一步提升系统整体能力,更好的满足实时数仓及HTAP等业务场景的需求。
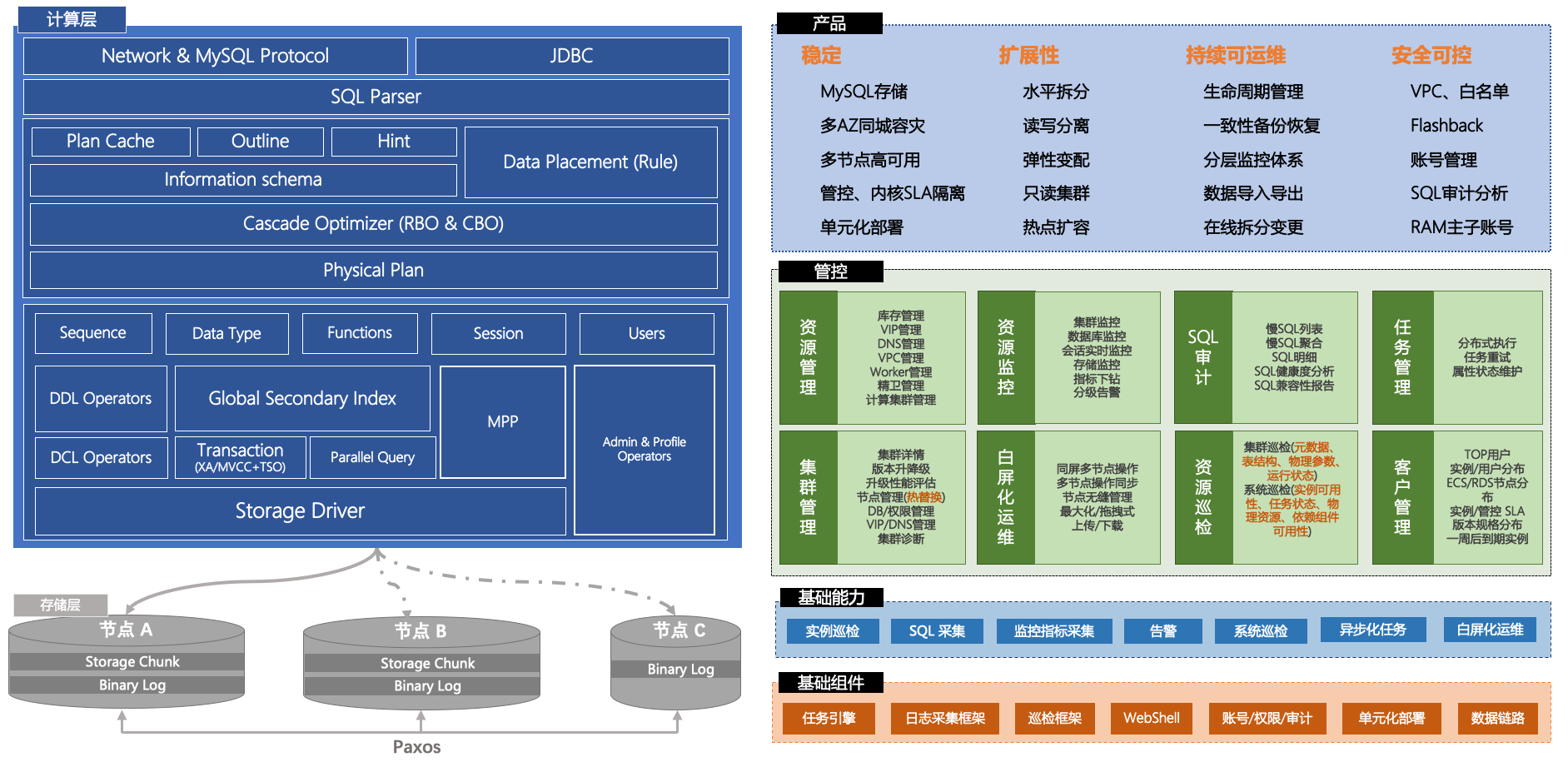
腾讯TDSQL MySQL
来源:https://cloud.tencent.com/product/dcdb
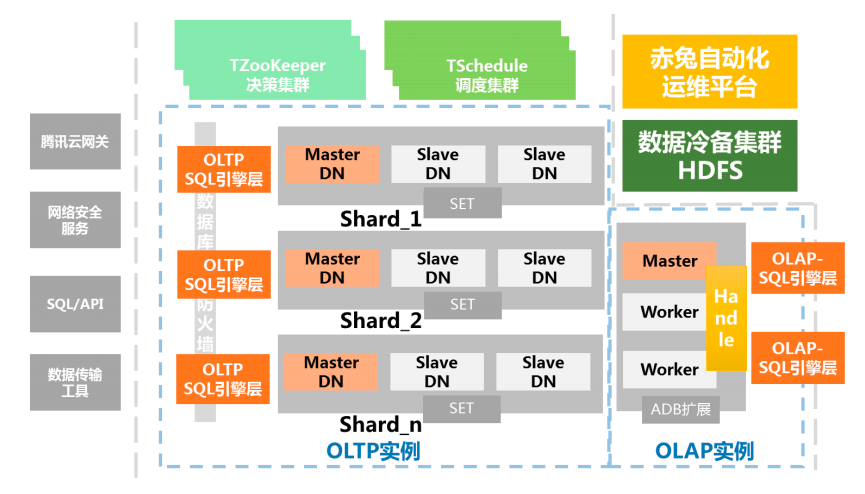
实例:从业务视角看到的一个具有完整能力的数据库;
分片(Sharding):是由数据库节点组(SET)和 SQL Engine(SQL Engine)和支撑系统组成一主多从数据库,也是水平拆分后承载数据的基本单元;
节点组(SET):由数据库节点(DataNode)组成的,通常包括一个主、从节点的集合。说明:云数据库支持虚拟化多租户能力,节点即可以是物理节点(一台物理设备),也可以是逻辑节点(一台物理设备的一部分资源)
SQL 引擎层(SQL Engine):账号鉴权、管理连接、SQL 解析、分配路由的 SQL Engine模块;SQL Engine 可以混合部署在数据库节点(DataNode)之上,也可以独立部署在一台物理机中。SQL Engine 也是采用分布式架构设计,提供并行负载和高可用容灾能力;调度集群、决策集群:作为集群的管理调度中心,主要保证数据库节点组、接入 SQL Engine 集群的正常运行;
⚫ 调度集群(Scheduler): 帮助 DBA 或者数据库用户自动调度和运行各种类型的作业,比如数据库备份、收集监控、生成各种报表或者执行业务流程等等,TDSQL 把 Schedule、Zookeeper、Oss(运营支撑系统)结合起来,通过时间窗口激活指定的资源计划,完成数据库在资源管理和作业调度上的各种复杂需求,Oracle 也用 DBMS_SCHEDULER 支持类似的能力。
⚫ 决策集群(ZooKeeper):在 TDSQL 中,它的主要功能是配置维护、选举决策、路由同步等,ZooKeeper 支撑数据库节点组(分片)的创建、删除、替换等工作,集群部署要求大于等于 3组且跨机房部署。
TDSpark 节点:基于 Spark 扩展的计算节点,采用只读的方式与 SET 连接,以 JDBC的方式获取数据。
赤兔运营平台(chitu):基于 TDSQL 定制开发的一套综合的业务运营和管理平台,将
数据库的管理特点,将网络管理、系统管理、监控服务有机整合在一起。
达梦MPP
来源:https://www.modb.pro/doc/252

DM MPP 中的每一个 DM 数据库服务器实例作为一个执行节点,简称 EP。客户端可连接任意一个 EP 节点进行操作,所有 EP 对客户来说都是对等的。
DM MPP 系统内每个 EP 只负责自身部分数据的读写,执行计划在所有 EP 并行执行,能充分利用各 EP 的计算能力及发挥各 EP 独立存储的优势。数据只在必要时通过 DM 的高速邮件 MAL 系统在 EP 间传递。当通信代价占整体执行代价的比例较小时,更能体现大规模并行处理的优势,随着系统规模的扩大,并行支路越多,优势越明显。
Flink 架构图
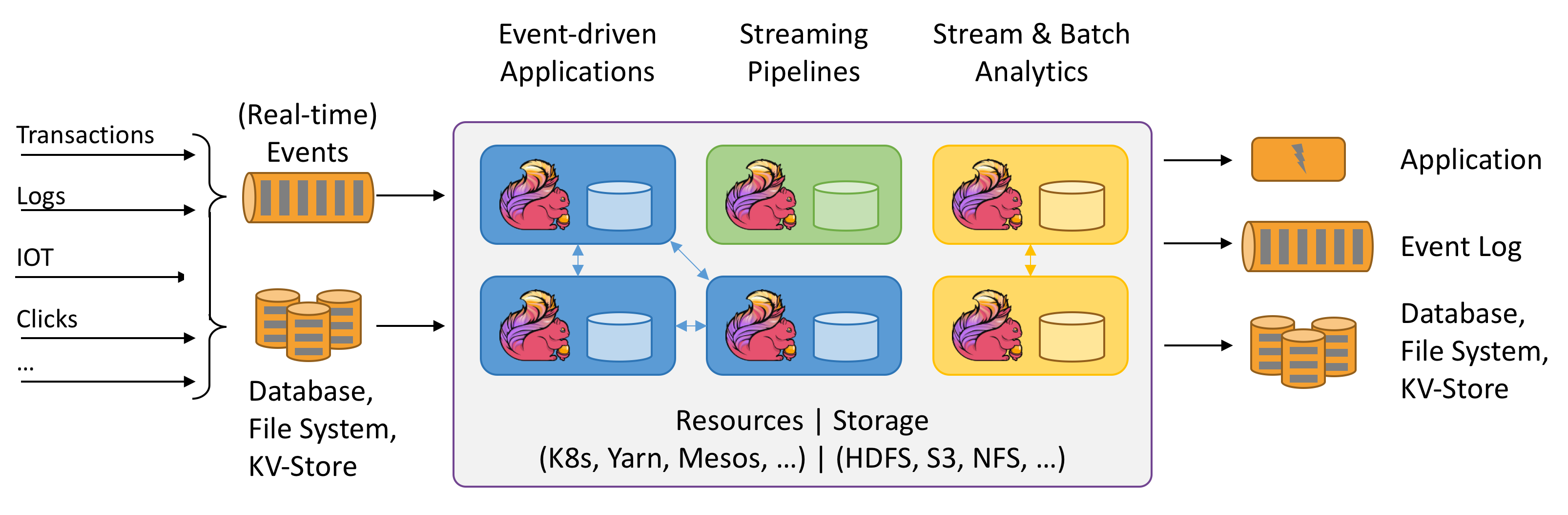
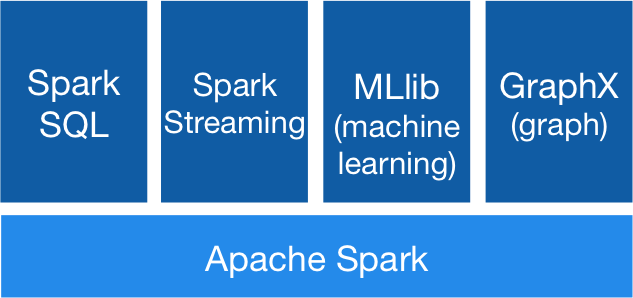
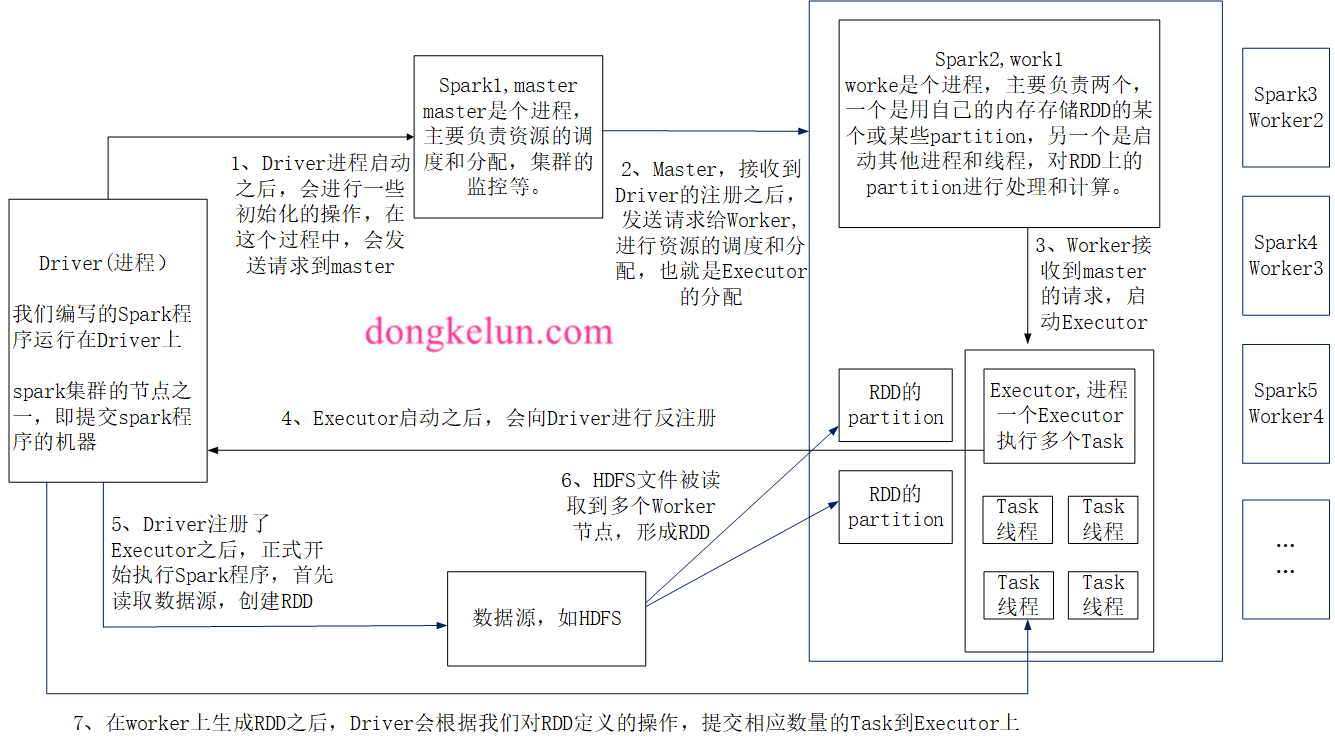
Spark架构图
来源:https://new.qq.com/rain/a/20210525A006XF00
https://dongkelun.com/2018/06/09/sparkArchitecturePrinciples/
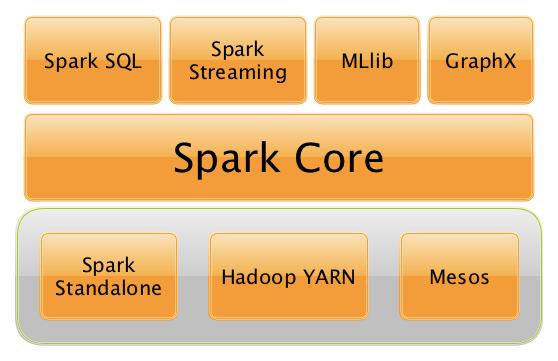
一个详细图
Clickhouse 架构图
官网没有图: https://clickhouse.tech/docs/zh/development/architecture/
第三方找到的图:https://segmentfault.com/a/1190000039292250?utm_source=tag-newest
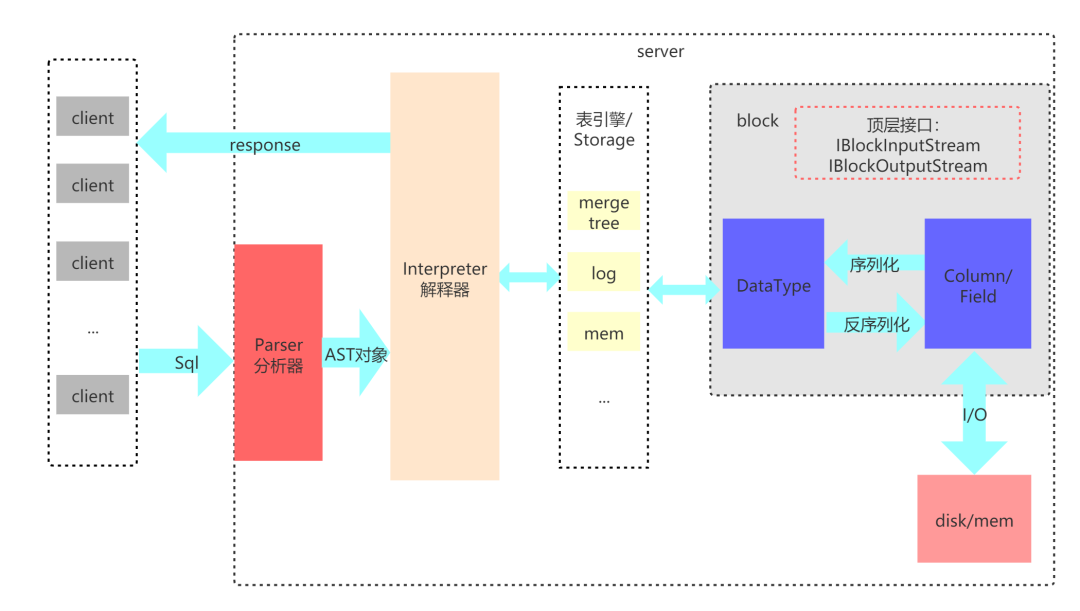
1)Parser与Interpreter
Parser和Interpreter是非常重要的两组接口:Parser分析器是将sql语句已递归的方式形成AST语法树的形式,并且不同类型的sql都会调用不同的parse实现类。而Interpreter解释器则负责解释AST,并进一步创建查询的执行管道。Interpreter解释器的作用就像Service服务层一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。首先它会解析AST对象;然后执行"业务逻辑" ( 例如分支判断、设置参数、调用接口等 );最终返回IBlock对象,以线程的形式建立起一个查询执行管道。
2)表引擎
表引擎是ClickHouse的一个显著特性,上文也有提到,clickhouse有很多种表引擎。不同的表引擎由不同的子类实现。表引擎是使用IStorage接口的,该接口定义了DDL ( 如ALTER、RENAME、OPTIMIZE和DROP等 ) 、read和write方法,它们分别负责数据的定义、查询与写入。
3)DataType
数据的序列化和反序列化工作由DataType负责。根据不同的数据类型,IDataType接口会有不同的实现类。DataType虽然会对数据进行正反序列化,但是它不会直接和内存或者磁盘做交互,而是转交给Column和Filed处理。
4)Column与Field
Column和Field是ClickHouse数据最基础的映射单元。作为一款百分之百的列式存储数据库,ClickHouse按列存储数据,内存中的一列数据由一个Column对象表示。Column对象分为接口和实现两个部分,在IColumn接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以及用于过滤的filter方法等。而这些方法的具体实现对象则根据数据类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和ColumnTuple等。在大多数场合,ClickHouse都会以整列的方式操作数据,但凡事也有例外。如果需要操作单个具体的数值 ( 也就是单列中的一行数据 ),则需要使用Field对象,Field对象代表一个单值。与Column对象的泛化设计思路不同,Field对象使用了聚合的设计模式。在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
5)Block
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了流的形式。虽然Column和Filed组成了数据的基本映射单元,但对应到实际操作,它们还缺少了一些必要的信息,比如数据的类型及列的名称。于是ClickHouse设计了Block对象,Block对象可以看作数据表的子集。Block对象的本质是由数据对象、数据类型和列名称组成的三元组,即Column、DataType及列名称字符串。Column提供了数据的读取能力,而DataType知道如何正反序列化,所以Block在这些对象的基础之上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过Block对象就能完成一系列的数据操作。在具体的实现过程中,Block并没有直接聚合Column和DataType对象,而是通过ColumnWith TypeAndName对象进行间接引用。
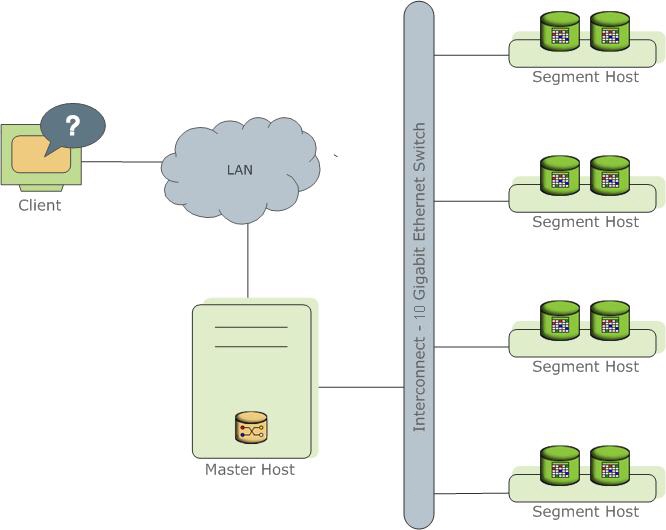
Greenplum 架构图
来源:https://docs.greenplum.org/6-13/admin_guide/intro/arch_overview.html
https://www.sohu.com/a/235952294_747818
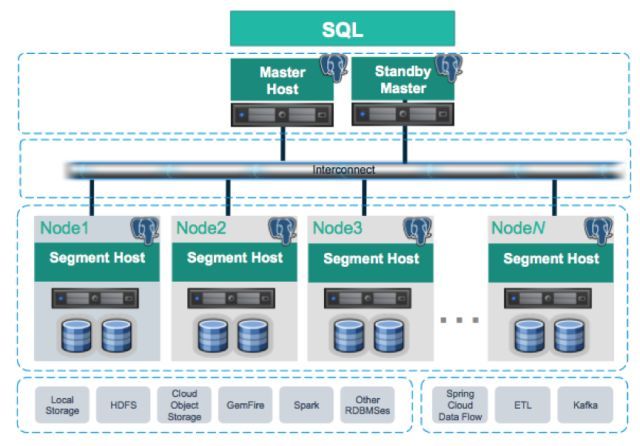
Gaussdb for opengauss_架构图
来源:https://support.huaweicloud.com/productdesc-opengauss/opengauss_01_0002.html
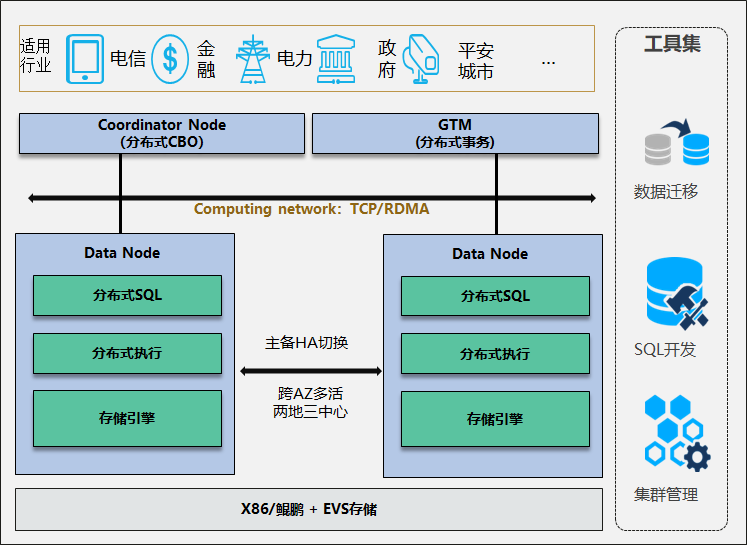
Gaussdb200架构图
来源:https://bbs.huaweicloud.com/blogs/102536
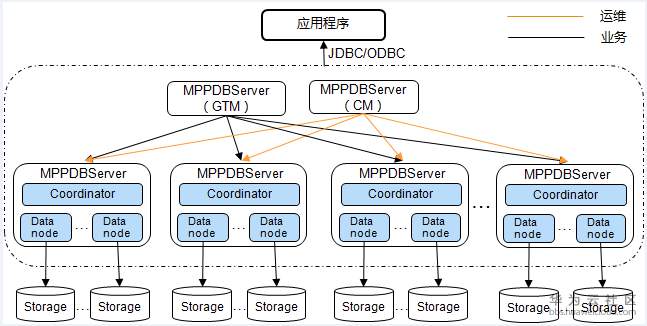
Gaussdb200架构说明如下图
Polardb整体架构图
如下几个不同的数据库从架构上是相同的。
polardb-O来源:https://help.aliyun.com/document_detail/173254.html
polardb Mysql来源:https://help.aliyun.com/document_detail/58766.html
PolarDB-X 整体架构图
来源:https://help.aliyun.com/document_detail/117771.html
GBase 8a整体架构图
来源:http://www.gbase.cn/pro/361.html

OceanBase 整体架构图
来源 https://www.oceanbase.com/docs/oceanbase-database/oceanbase-database/V3.1.1/system-architecture
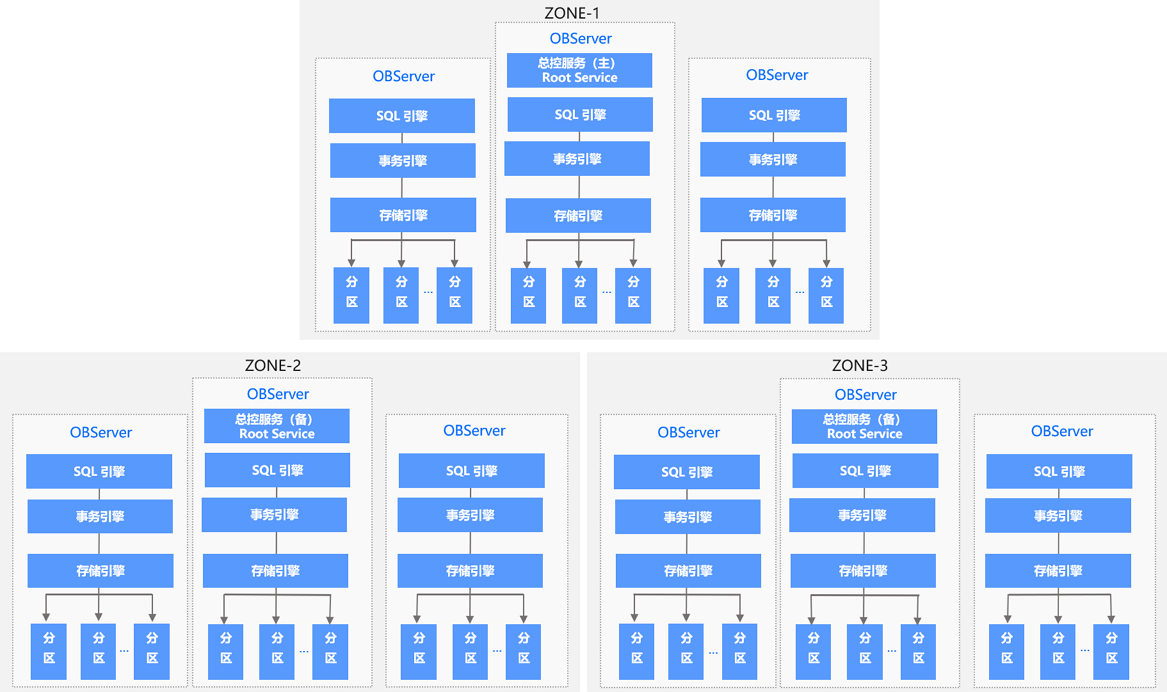
OceanBase 数据库支持数据跨地域(Region)部署,每个地域可能位于不同的城市,距离通常比较远,所以 OceanBase 数据库可以支持多城市部署,也支持多城市级别的容灾。一个 Region 可以包含一个或者多个 Zone,Zone 是一个逻辑的概念,它包含了 1 台或者多台运行了 OBServer 进程的服务器(以下简称 OBServer)。每一个 Zone 上包含一个完整的数据副本,由于 OceanBase 数据库的数据副本是以分区为单位的,所以同一个分区的数据会分布在多个 Zone 上。每个分区的主副本所在服务器被称为 Leader,所在的 Zone 被称为 Primary Zone。如果不设定 Primary Zone,系统会根据负载均衡的策略,在多个全功能副本里自动选择一个作为 Leader。
每个 Zone 会提供两种服务:总控服务(RootService)和分区服务(PartitionService)。其中每个 Zone 上都会存在一个总控服务,运行在某一个 OBServer 上,整个集群中只存在一个主总控服务,其他的总控服务作为主总控服务的备用服务运行。总控服务负责整个集群的资源调度、资源分配、数据分布信息管理以及 Schema 管理等功能。 其中:
- 资源调度主要包含了向集群中添加、删除 OBServer,在 OBServer 中创建资源规格、Tenant 等供用户使用的资源;
- 资源均衡主要是指各种资源(例如:Unit)在各个 Zone 或者 OBServer 之间的迁移。
- 数据分布管理是指总控服务会决定数据分布的位置信息,例如:某一个分区的数据分布到哪些 OBServer 上。
- Schema 管理是指总控服务会负责调度和管理各种 DDL 语句。
分区服务用于负责每个 OBServer 上各个分区的管理和操作功能的模块,这个模块与事务引擎、存储引擎存在很多调用关系。
OceanBase 数据库基于 Paxos 的分布式选举算法来实现系统的高可用,最小的粒度可以做到分区级别。集群中数据的一个分区(或者称为副本)会被保存到所有的 Zone 上,整个系统中该副本的多个分区之间通过 Paxos 协议进行日志同步。每个分区和它的副本构成一个独立的 Paxos 复制组,其中一个分区为主分区(Leader),其它分区为备分区(Follower)。所有针对这个副本的写请求,都会自动路由到对应的主分区上进行。主分区可以分布在不同的 OBServer 上,这样对于不同副本的写操作也会分布到不同的数据节点上,从而实现数据多点写入,提高系统性能。
TiDB整体架构图
来源:https://docs.pingcap.com/zh/tidb/stable/tidb-architecture
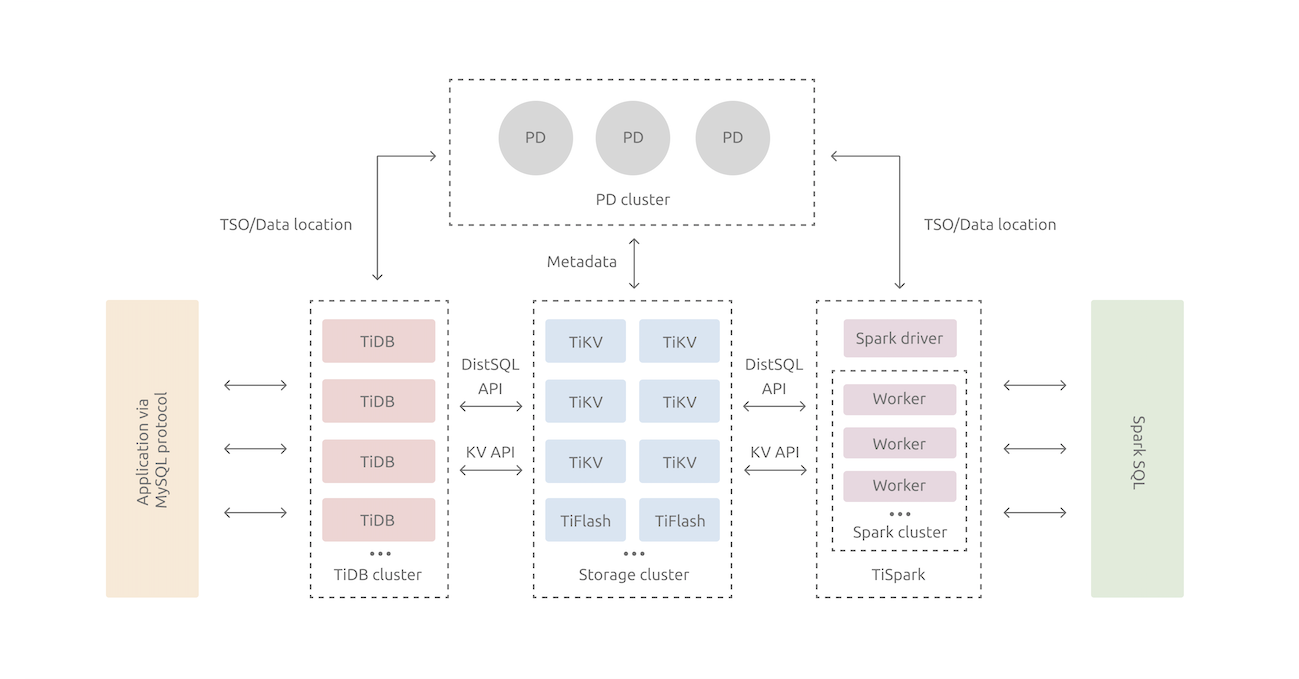
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。