Brin Index在Greenplum 7中的理论与实现
《Greenplum 7新版本大剧透》系列 II
🏷️主题: Brin Index在Greenplum 7中的理论与实现
⏰时间:2021年4月28日 20:00-21:00
演讲大纲:
1、Append Only Table简介
2、Brin Index简介
3、Brin Index on Append Only Table的实现原理
4、性能特性描述和测试结果
直播链接:https://www.modb.pro/event/301


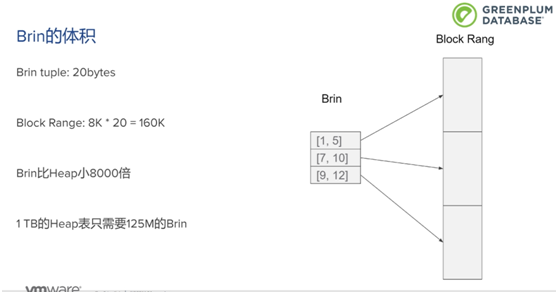
Btree数据空间占用量和原始数据几乎是一样的。
大部分OLAP数据库符合这个场景。常规索引占用空间太大,不适合。

segscan 全表扫描。
brin索引一个或一组block。

如果新增加值落在范围之内,则不需要更新BRIN
删除某条数据,范围不变化。

普通Bacuum 不做任何操作,而vacuum full 发生可block之间的数据移动,重建索引。

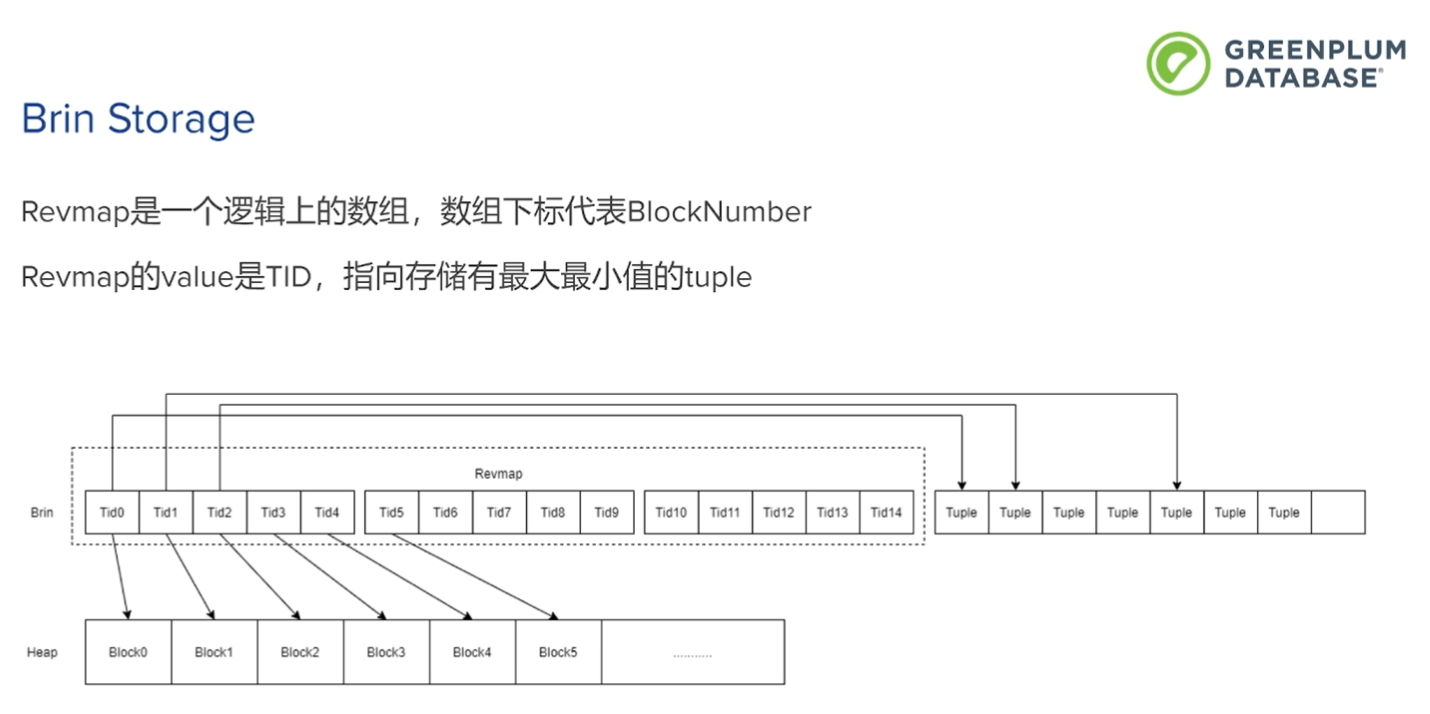
Brin Storage 存储结构

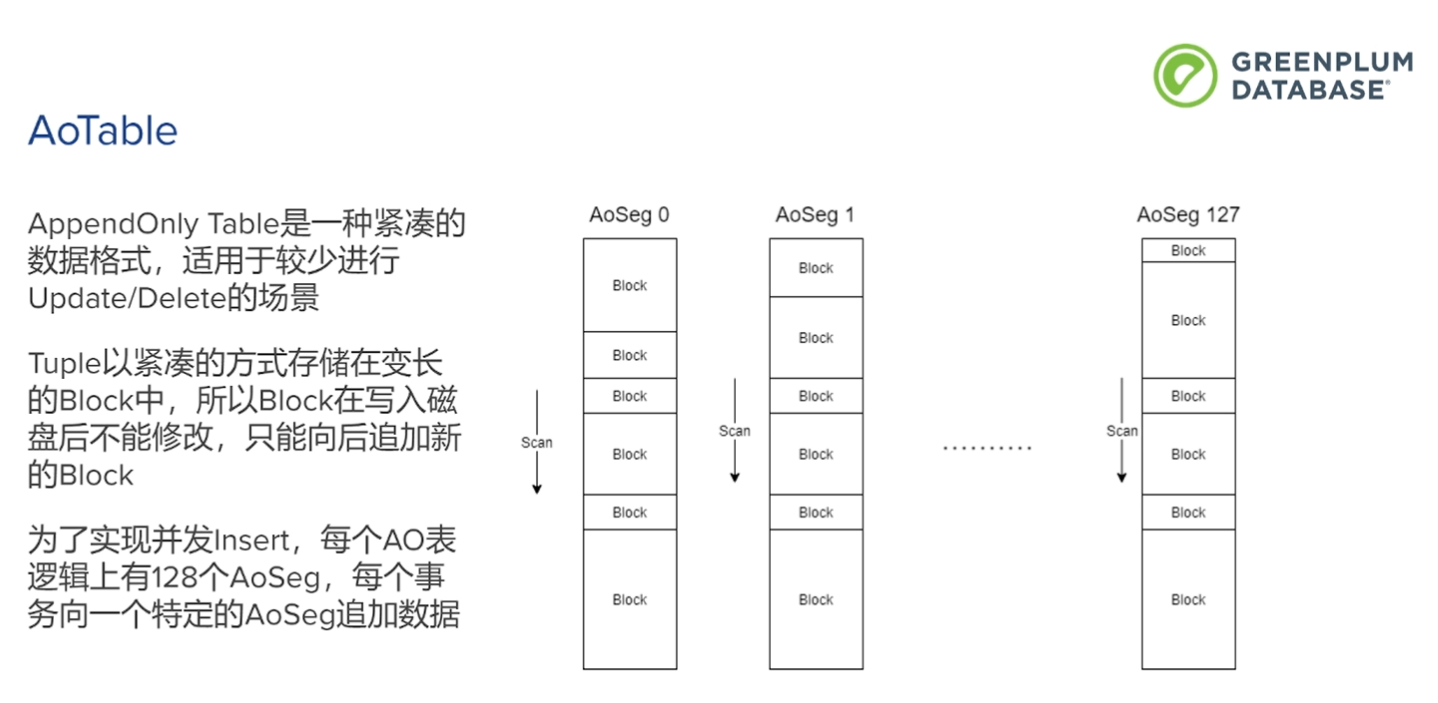
heap表占用空间很大,适合update,不适合OLAP的顺序扫描。
写入的不能在修改,只能后面追加。
每个AO表,逻辑上有128个aoseg, 每个并发向特定的aoseg追加数据。
Brin是一维的连续结构,而AO是多个不连续的。
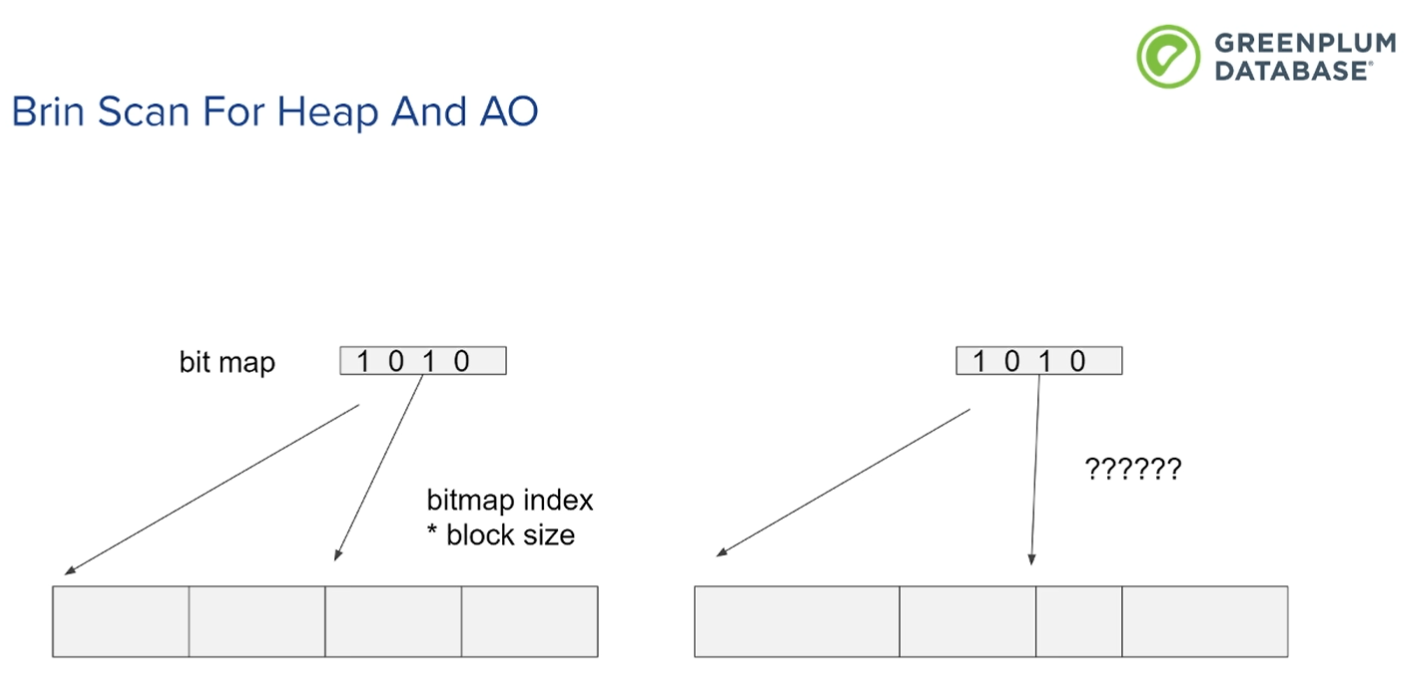
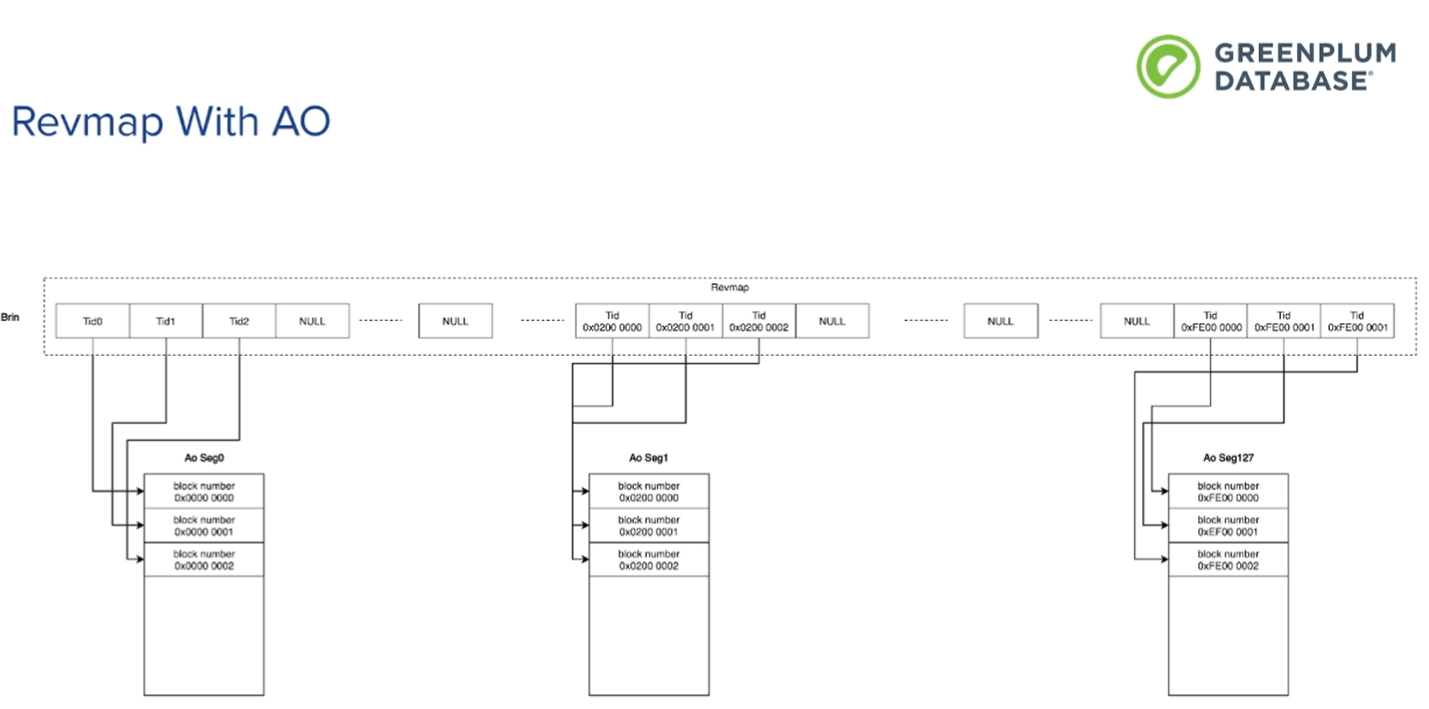
通过tuple ID, block number和偏移量。 使用逻辑block..
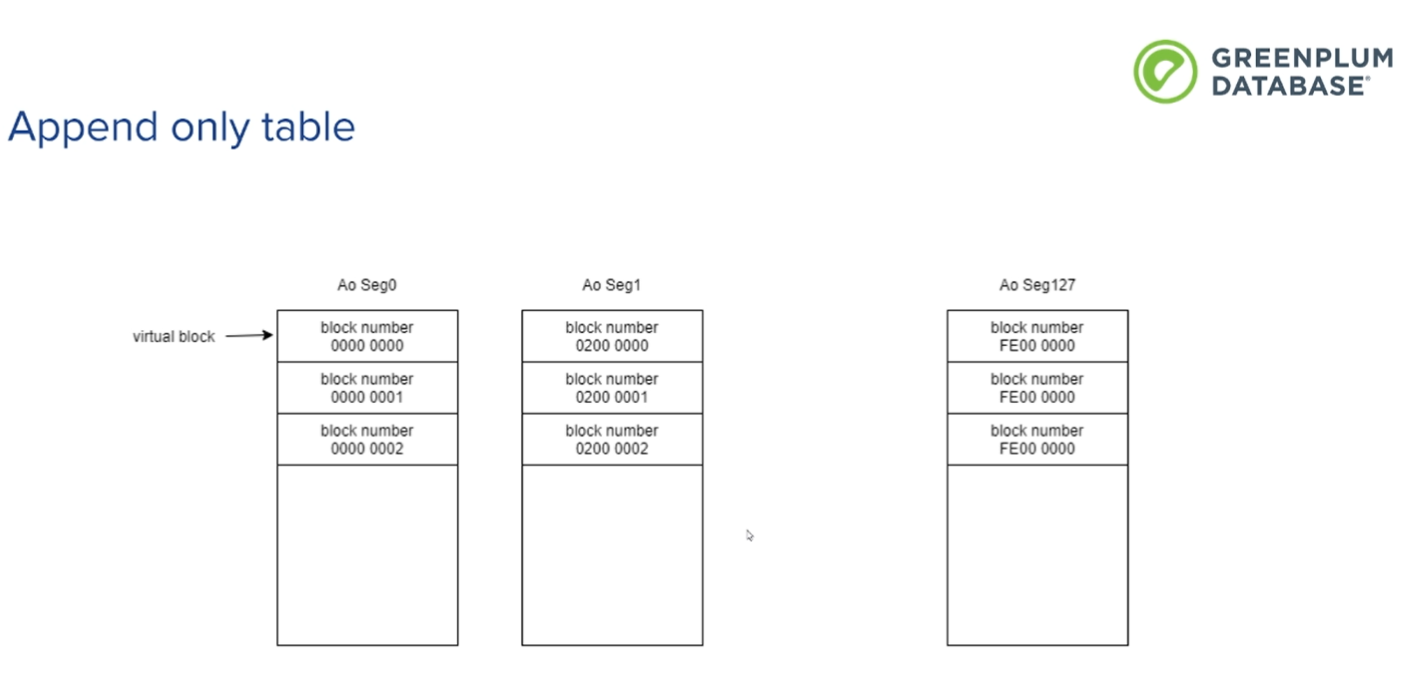
128个aoseg 的block number是分散到每个aoseg里面的。 各自占用一部分 2的32次方/128*aoseg编号
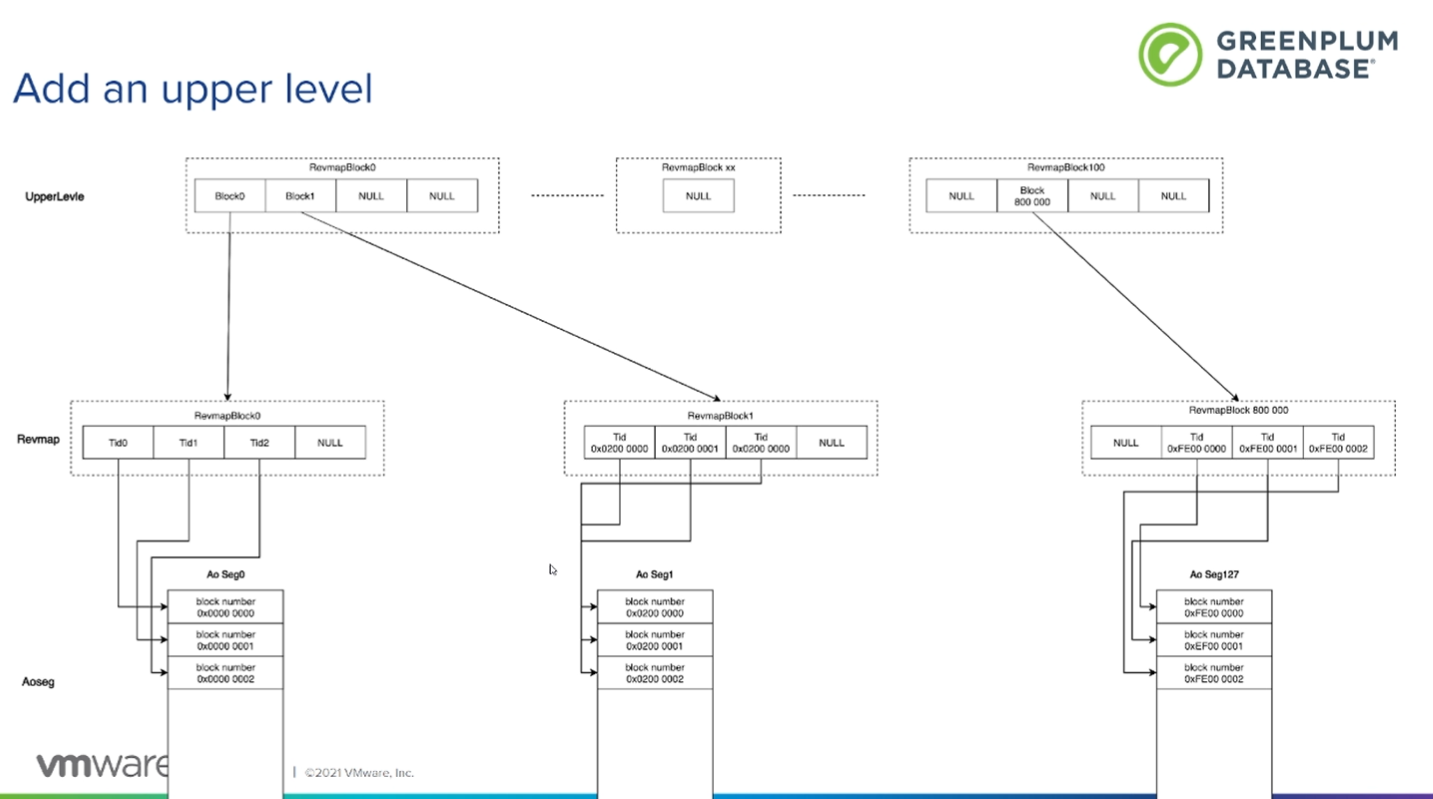
增加上层结构 upperLevel 记录的是revmap block的block number




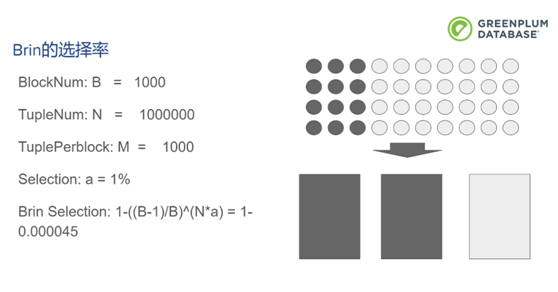
千万分之一的选择率
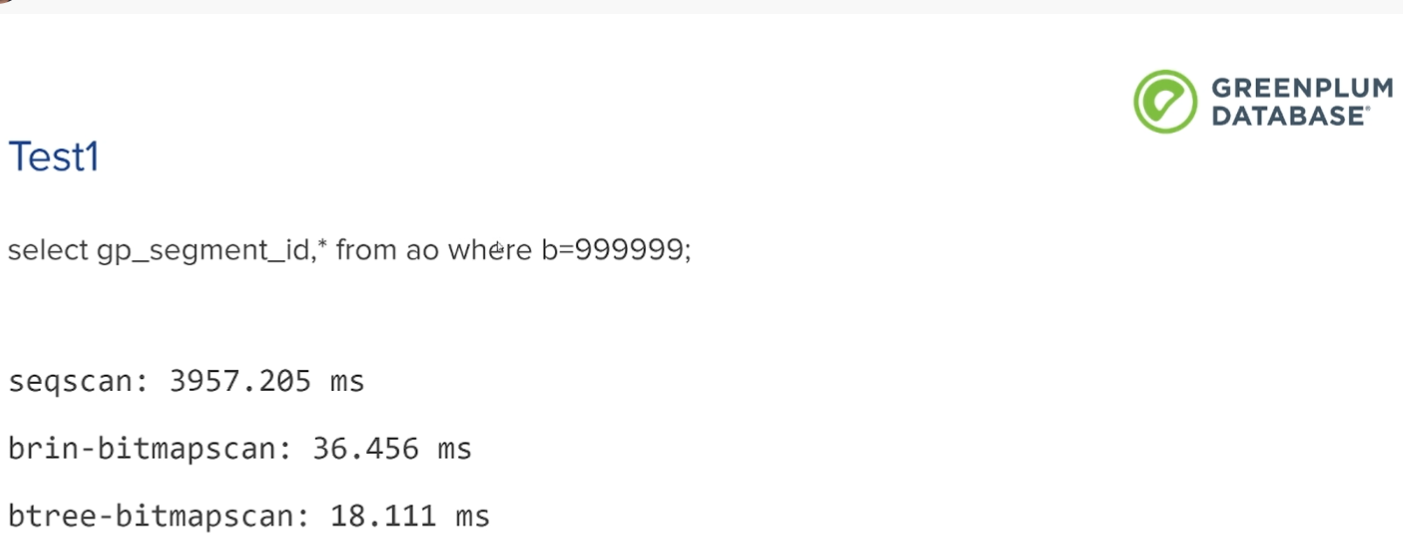
千分之一的选择率

10%的选择率

空间占用

QA
Q:对字符串有效吗?
A:可以,可以比较大小的都可以
Q:1个brin对应的block数是固定20个吗?
A:有参数限制
Q:根据时间范围查询的时序数据,使用brin index是否合适?我自己在postgresql上做的性能对比测试来看,btree性能还是要比brin要好的
A:brin代价小,性能凑合。 btree代价大,性能好
Q:gp在是基于pg开发的吗?做了那些改变使gp适合了OLAP的场景了?pg主要还是用在TP场景吧?
A: 查询优化器和执行优化器。 分布式改造,适合OLAP场景。 存储上实现了AO表。