本文介绍目前了解到的GreenPlum 7的新版本特性,包括BRIN索引,扩展的统计分析,UpSert, JIT编译,新的分区表,AM以及存储过程内部支持事务等方面。
目录导航
参考
https://www.bilibili.com/video/BV1nV411h7Zv/?aid=415632377&cid=269662128&page=1
特性总结
- 稀疏索引(Block Range Index BRIN),通过pages_per_range控制范围
- 额外的扩展统计分析:多列之间关系,提升执行计划评估准确度
- UpSert, 一个SQL在执行失败后,可以指定行为。看例子类似Merge 比如Insert时主键冲突如ON CONFLICT DO NOTHING 啥都不做忽略,或者ON CONFLICT DO UPDATE 做更新。
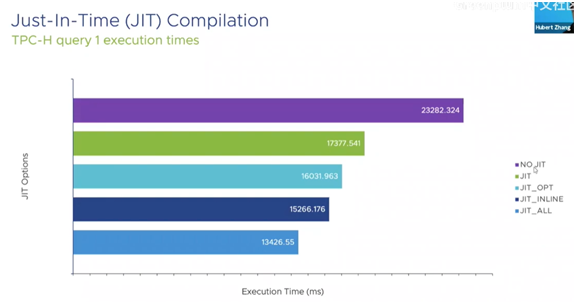
- JIT编译,提升CPU相关操作的性能。居于COST确认是否开启,性能23秒提升到13秒,接近40%。
- 分区表。子分区是顶级表,支持attach和deattch将顶层表,挂到分区表,且同级子分区的方式可以不同。
- Table Access Method(AM)。把执行器和存储引擎之间高度的抽象化。没看到具体影响。
- 支持在存储过程内部做事务提交和回滚。
BRIN稀疏索引
在指定范围内,记录数据的最大值,最小值等信息,来提升扫描的效率。和GBase的智能索引,Click的稀疏索引一致。提供了参数指定索引范围。

Extended Statistics 额外的统计分析
分析不同列之间的依赖关系,比如地址和邮编,是有关联的。2个列做distinct和单个的结果几乎一样。多列数据的distinct值、多列的MCV Most column value等,提升执行计划的评估准确度。

UpSert
避免一个异常导致整个事务全部回滚。
on conflict do nothing

ON CONFLICT DO UPDATE

JIT编译
在运行中,将一个可执行程序,转化成native本地的。如下的a=3, sum等都要进行多次函数调用。通过jit可以加速优化。对CPU绑定的查询有很好的效果。JIT自身在转化为native时也是需要代价的。通过COST来控制什么时候运用JIT。
JIT在GP里面的实现,基于LLVM做的。
- 最重要的目标是对表达式的加速。包括wehere, 目标列,聚集函数等。
- 提升从磁盘deforming到内存的过程。
- 把函数进行inline 生成代码的优化
开启JIT不同参数的效果,优化全开的话,耗时从23秒降低到13秒。
Partitioned Tables 新的分区表
有语法的变动。额外兼容PG的语法,单独创建一级、二级的分区。其中分区表,变成了一级表。允许分区表,没有分区(0个partition),支持异构的分区。

一个分区表的子分区,分布方式允许不同(一个list,一个range)。提供了更多的灵活性。新建一个分区表,可以attach到另外一个分区表作为分区。通过detach取消关联。

Table Access Method(AM)
把执行器和存储引擎之间高度的抽象化。对ao_row和ao_column做了适配。未看到实质性提升描述。

存储过程中的事务
可以在存储过程内部执行事务,Commit/Rollback。
在6中,truncate在循环内部是没有办法提交的。在7里可以执行commit来回收空间。实现在循环内部及时回收,避免OOM问题。
