https://zhuanlan.zhihu.com/p/125573685
Raft协议是一种分布式一致性协议,相对Paxos协议,他更好理解,下面我们来全面分析一下他的执行原理。
目录导航
分布式一致性
首先从一个简单例子入手,假设有个单节点系统(假设这个单点系统是个数据库系统),从客户端写入一个新值到服务器节点,如下图所示
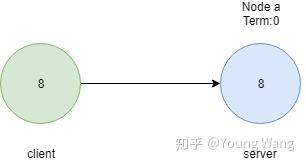
正所谓一人吃跑,全家不饿,很明显,只要成功写入一个节点就行了,在单一节点上实现一致性是如此简单。
但话说回来,在企业级生产环境下单点部署几点几乎不可能,如何在多节点系统下保持一致性呢?这就是我们需要讨论的话题——分布式一致性。
Raft协议概述
Raft是分布式一致性的实现协议,我们先从更高层次大概了解一下他大概是如何工作的(在本文后面部分再深入剖析工作细节,比如选主过程、日志复制)。
一个节点有3种状态:
- Follower state.
- Candidate state.
- Leader state.
一开始,所有节点都是Follower状态,我们认为这些处于Follower状态的节点叫Follower(追随者),如下图所示:
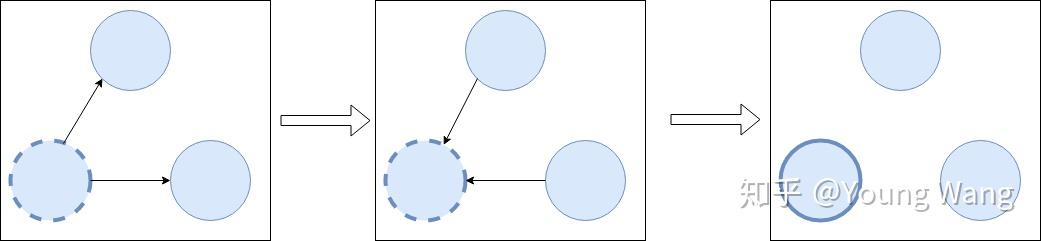
当所有的Follower都无法感知到leader存在时,这是他们会变成一个candidate(参选者),candidate可以向其他节点发起投票,其他节点反馈投票结果,即是同意还是驳回,如果此次投票获得了大部分节点的同意,则candidate成为了新的leader,这个过程就叫Leader Election(Leader选举),如下图所示
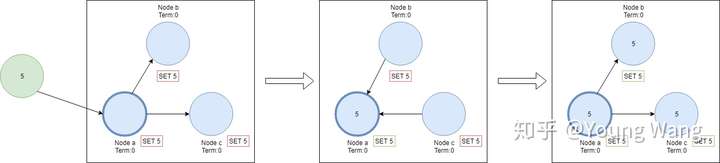
Leader选出来之后,任何改变都需要通过Leader来传达,做法是:每一次变更都会作为一个entry加入到Leader节点日志中,这时entry的状态是未提交状态(uncommitted),所以这并不会改变节点的当前值。为了能够提交entry,首先需要做的是将entry复制到所有Follower节点,然后leader开始等待直到大部分节点都写入成功了entry为止,最后leader 提交entry,节点值发生变更,并通知所有Follower entry is committed,最后所有节点都达到了一致的状态,这个过程叫做日志复制。整个过程如下:
Leader选举过程
Raft协议种存在两个超时设置用来控制选举过程,第一个超时设置是选举超时(election timeout),选举超时用来设置一个节点从Follower变成一个candidate所需要等待的时间,这个等待时间控制在150ms到300ms之间,这个等待时间是随机的,随机是为了尽量避免产生多个candidate,给选主过程制造麻烦。candidate产生如下图所示
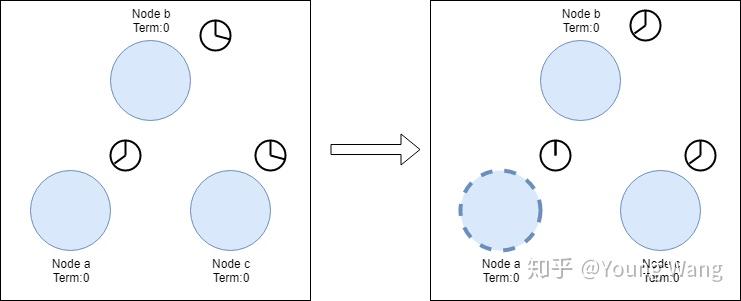
当3个节点都设置election timeout时,节点a跑得比其他其他节点快些成为第一个candidate,并开始发起第一轮选举。节点首先给自己先投一票,然后向其他节点发送Request Vote消息。
如果其他节点收到消息后发现并没有进行过此次投票,则他就会为candidate进行一次投票并重置election timeout,一旦candidate获得了大多数选票(大多数保证每一轮选举只有一个candidate会获胜),则他就会变成leader,如下图所示:
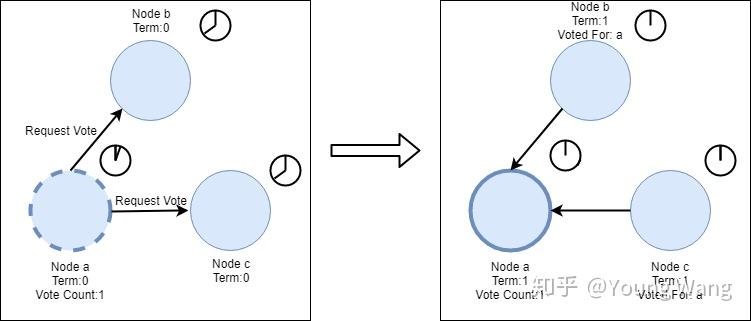
节点a成为leader后,会间隔指定时间发送Append Entries消息给他的Follower,间隔时间是由心跳超时控制的(heartbeat timeout,即第二种超时类型),fower收到消息后会重置等待时间,这样就能阻止Follower成为candidate。心跳检测过程如下:
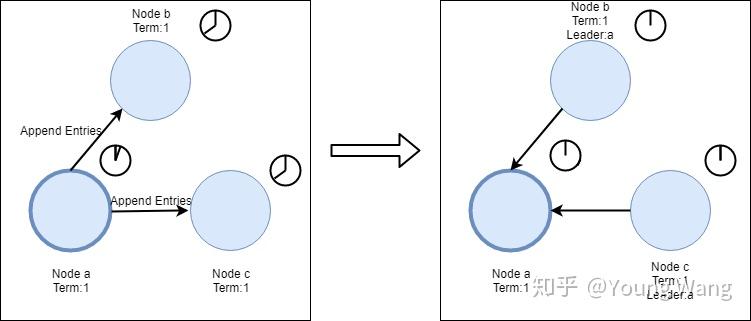
这个过程会一直持续下去直到一个Follower停止接收heatbeats,并且成为candidate为止。
以上就是一个常规选主过程。
上文我们提到在Follower转变成candidate过程中会随机分配一个election timeout给每个节点,这样做可以尽量避免产生多个candidate,但并不能100%保证不出现2个candidate的情况。当出现了2个节点成为candidate,此时需要如何确保选主顺畅呢?
假设节点a、b、c同时成为candidate,并且各自发起了新一轮的选举,选举过程如下
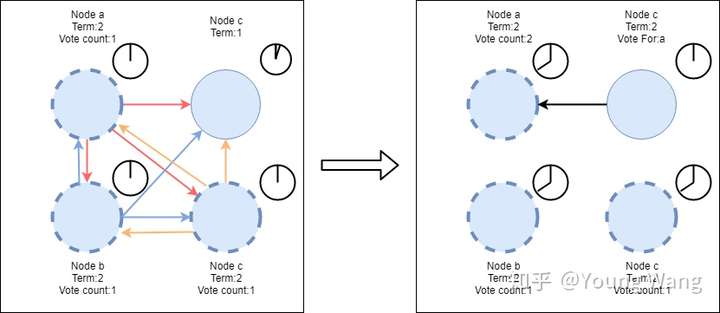
从图中我们可以看到,a节点获取了2张选票,比其他candidate多,但很可惜,由于仍没有满足大多数原则(vote count需>= 4/2 +1),此论选举失败,在休眠一段时间后,节点会再次重试从Follower -> candidate -> leader的选举过程,直到产生Leader为止。
日志复制
一旦我们选出了主,那么主就有责任将系统发生的所有变更复制到所有节点。主会使用和心跳相同的Append Entries消息用来复制。首先,客户端发起写入值变更,主会在下一个心跳到来时发送变更日志到Follower,当主收到大多数Follower确认后,提交变更entry,然后向客户端返回成功。这个过程正如我们在概述小节描述的一样。
set a = 5:
Raft牛逼之处在于网络分区(比如节点部署在不同机房,不同网段)下仍然可以确保节点数据一致。
假设有5个节点(abcde)组成的网络,ab位于一个机房,cde唯一一个机房,此时的leader是a节点。由于网络故障造成2个机房节点通信失败,位于一个机房的cde发现leader心跳不再了,则发起了选主过程,节点c获得了多数选票成为了新的Leader,此时5个节点同时存在2 Leader(老leade a节点,新leader c节点),如图所示:
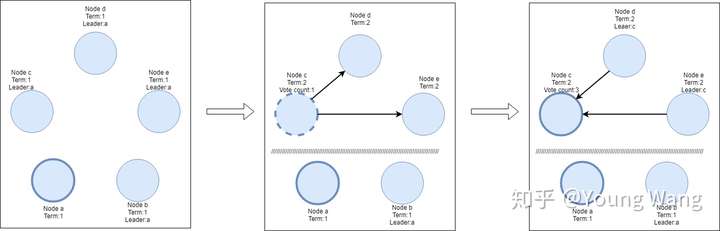
接着,我们新增一个客户端节点,该节点尝试修改a的值为3,由于节点a无法与cde通信,在做日志复制时无法得到大多数的应答,那么这条entry将一直是uncommited状态。而另个客户端尝试修改节点c的值为8,由于他可以获得大多数的应答,所以这次操作entry可以正常提交。
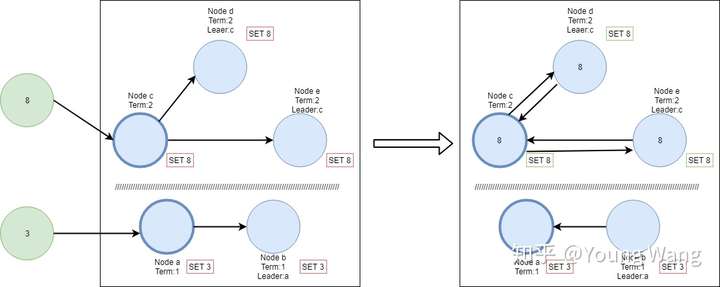
现在网络故障恢复了,节点a和b都会广播心跳并携带,此时节点b发现了更高的election term,则自动将自己降级为follower,且a和b同时需要回滚他们为提交的entries,并且匹配new leader日志,如下图所示

好,差不多讲完了,觉得有收获麻烦点个赞,谢谢。
The end.
转载请注明来源,否则严禁转载。