本文针对GBase 8a数据库集群的执行计划功能(Explain),采用从简单入门到复杂用例讲解常用SQL,逐步解读执行计划的使用方法,包括单表聚合group, 排序order,以及多表join等情况,并考虑到随机分布表,Hash分布表和复制表等情况。
文中的初,中,高,分别表示执行计划的复杂度。对于多级嵌套等情况,实际都是这些基本单元的组合。
目录导航
参考
执行计划各个步骤,各参数的含义,请参考如下文章。
环境
节点数
2节点集群。
[root@rh6-1 ~]# gcadmin
CLUSTER STATE: ACTIVE
CLUSTER MODE: NORMAL
=================================================================
| GBASE COORDINATOR CLUSTER INFORMATION |
=================================================================
| NodeName | IpAddress |gcware |gcluster |DataState |
-----------------------------------------------------------------
| coordinator1 | 10.0.2.201 | OPEN | OPEN | 0 |
-----------------------------------------------------------------
=============================================================
| GBASE DATA CLUSTER INFORMATION |
=============================================================
|NodeName | IpAddress |gnode |syncserver |DataState |
-------------------------------------------------------------
| node1 | 10.0.2.201 | OPEN | OPEN | 0 |
-------------------------------------------------------------
| node2 | 10.0.2.202 | OPEN | OPEN | 0 |
-------------------------------------------------------------
集群版本
8.6.2.43
[gbase@rh6-1 ~]$ gccli -e"select version()"
+----------------------+
| version() |
+----------------------+
| 8.6.2.43-R28 .125499 |
+----------------------+
数据
随机分布表T1和t1_2
注意其数据量差距,t1是3300万行,t1_2是1000行。
CREATE TABLE "t1" (
"id" int(11) DEFAULT NULL,
"name" varchar(100) DEFAULT NULL
) ENGINE=EXPRESS
gbase> create table t1_2 like t1;
Query OK, 0 rows affected (Elapsed: 00:00:00.65)
gbase> select count(*) from t1;
+----------+
| count(*) |
+----------+
| 33000001 |
+----------+
1 row in set (Elapsed: 00:00:00.50)
gbase> select count(*) from t1_2;
+----------+
| count(*) |
+----------+
| 1000 |
+----------+
1 row in set (Elapsed: 00:00:00.68)
Hash分布表td (Distribution)
CREATE TABLE "td" (
"id" int(11) DEFAULT NULL,
"name" varchar(100) DEFAULT NULL
) ENGINE=EXPRESS DISTRIBUTED BY('id')
gbase> create table td_2 like td;
Query OK, 0 rows affected (Elapsed: 00:00:00.49)
gbase> select count(*) from td;
+----------+
| count(*) |
+----------+
| 33000001 |
+----------+
1 row in set (Elapsed: 00:00:00.16)
gbase> select count(*) from td_2;
+----------+
| count(*) |
+----------+
| 1000 |
+----------+
1 row in set (Elapsed: 00:00:01.03)
Hash分布表td_name(分布列不同)
CREATE TABLE "td_name" (
"id" int(11) DEFAULT NULL,
"name" varchar(100) DEFAULT NULL
) ENGINE=EXPRESS DISTRIBUTED BY('name')
gbase> select count(*) from td_name;
+----------+
| count(*) |
+----------+
| 33000001 |
+----------+
1 row in set (Elapsed: 00:00:00.14)
复制表tr (Replicated)
CREATE TABLE "tr" (
"id" int(11) DEFAULT NULL,
"name" varchar(100) DEFAULT NULL
) ENGINE=EXPRESS REPLICATED【初】单表count(*)
目前不显示任何任何细节,内部就是各个节点自己count(*),然后将行数加在一起返回即可。
gbase> explain select count(*) from t1;
+------------------+
| QueryPlan |
+------------------+
| Count optimized. |
+------------------+
1 row in set (Elapsed: 00:00:00.01)
gbase> explain select count(*) from t1 where id>10;
+------------------+
| QueryPlan |
+------------------+
| Count optimized. |
+------------------+
1 row in set (Elapsed: 00:00:00.01)
【初】单表简单查询
无过滤条件
从如下执行计划看只有1步:
- MOTION:RESULT 将结果发送给调用端
- OPERATION:TABLE,代表无任何条件的单表操作。
- TABLE:T1[DIS],涉及到的表是T1, DIS表示随机分布
- CONDITION:空
gbase> explain select * from t1;
+----+----------+-----------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------+-----------------+
| 00 | [RESULT] | Table | t1[DIS] | | t1 |
+----+----------+-----------+---------+-----------+-----------------+
1 row in set (Elapsed: 00:00:00.00)
Hash分布表的TABLE显示为分布列[id]
gbase> explain select * from td;
+----+----------+-----------+--------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+-----------+-----------------+
| 00 | [RESULT] | Table | td[id] | | td |
+----+----------+-----------+--------+-----------+-----------------+
1 row in set (Elapsed: 00:00:00.00)
复制表的TABLE显示为[REP]
gbase> explain select * from tr;
+----+----------+-----------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------+-----------------+
| 00 | [RESULT] | Table | tr[REP] | | tr |
+----+----------+-----------+---------+-----------+-----------------+
1 row in set (Elapsed: 00:00:00.01)
带单个过滤条件
只有1步。
- MOTION:RESULT 将结果发送给调用端
- OPERATION:SCAN ,单表扫描,并使用条件过滤数据。
- TABLE:T1[DIS],涉及到的表是T1,分布表
- CONDITION:id{S} > 10,针对SCAN,为扫描条件 id>10
gbase> explain select * from t1 where id>10;
+----+----------+-----------+---------+--------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+--------------+-----------------+
| 00 | [RESULT] | SCAN | t1[DIS] | (id{S} > 10) | t1 |
+----+----------+-----------+---------+--------------+-----------------+
1 row in set (Elapsed: 00:00:00.00)
Hash分布表和复制表的基本相同,只是涉及的TABLE列不一样。
gbase> explain select * from td where id>10;
+----+----------+-----------+--------+--------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+--------------+-----------------+
| 00 | [RESULT] | SCAN | td[id] | (id{S} > 10) | td |
+----+----------+-----------+--------+--------------+-----------------+
1 row in set (Elapsed: 00:00:00.00)
gbase> explain select * from tr where id>10;
+----+----------+-----------+---------+--------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+--------------+-----------------+
| 00 | [RESULT] | SCAN | tr[REP] | (id{S} > 10) | tr |
+----+----------+-----------+---------+--------------+-----------------+
1 row in set (Elapsed: 00:00:00.00)
带多个过滤条件
执行计划和单个条件的基本一致,区别就是CONDITION条件列变成了多个,采用多行的形式显示。
注意其中的数字类型,被内部强制转换成char类型。
gbase> explain select * from t1 where id>10 and id<100 and id like '%3%';
+----+----------+-----------+---------+-----------------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------------------------------+-----------------+
| 00 | [RESULT] | SCAN | t1[DIS] | (id{S} > 10) | t1 |
| | | | | (id{S} < 100) | |
| | | | | (cast(id as char(11)) LIKE '%3%') | |
+----+----------+-----------+---------+-----------------------------------+-----------------+
3 rows in set (Elapsed: 00:00:00.00)
gbase> explain select * from td where id>10 and id<100 and id like '%3%';
+----+----------+-----------+--------+-----------------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+-----------------------------------+-----------------+
| 00 | [RESULT] | SCAN | td[id] | (id{S} > 10) | td |
| | | | | (id{S} < 100) | |
| | | | | (cast(id as char(11)) LIKE '%3%') | |
+----+----------+-----------+--------+-----------------------------------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
gbase> explain select * from tr where id>10 and id<100 and id like '%3%';
+----+----------+-----------+---------+-----------------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------------------------------+-----------------+
| 00 | [RESULT] | SCAN | tr[REP] | (id{S} > 10) | tr |
| | | | | (id{S} < 100) | |
| | | | | (cast(id as char(11)) LIKE '%3%') | |
+----+----------+-----------+---------+-----------------------------------+-----------------+
3 rows in set (Elapsed: 00:00:00.00)
【初】单表全排序
全排序对随机分布表和Hash分布表没有区别,都需要先拉到一个节点后,再进行。执行计划分成了2步:先从各个节点将数据发送到汇总节点的表里;然后在汇总表里,根据条件排序后,返回。
第00步。
- MOTION:GATHER 结果发给汇总节点
- OPERATION:TABLE 全表。
- TABLE:T1[DIS],T1表是分布表, td[id], td表是Hash分布表。
- CONDITION:空
第01步
- MOTION:RESULT 结果发给调用方客户端
- OPERATION:Step 使用前一步的结果。 Order 排序操作。
- TABLE:T1[DIS],00 第一步汇总节点的表
- CONDITION:对Order排序,指排序的条件
gbase> explain select * from t1 order by id ;
+----+----------+-----------+---------+-----------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | ORDER | | ORDER BY id ASC | |
| 00 | [GATHER] | Table | t1[DIS] | | t1 |
+----+----------+-----------+---------+-----------------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
gbase>
gbase> explain select * from td order by id ;
+----+----------+-----------+--------+-----------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+-----------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | ORDER | | ORDER BY id ASC | |
| 00 | [GATHER] | Table | td[id] | | td |
+----+----------+-----------+--------+-----------------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
对复制表,因为每个节点数据都是一样的,所以不需要汇总这一步,直接做排序返回即可。
gbase> explain select * from tr order by id ;
+----+----------+-----------+---------+-----------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------------+-----------------+
| 00 | [RESULT] | Table | tr[REP] | | tr |
| | | ORDER | | ORDER BY id ASC | |
+----+----------+-----------+---------+-----------------+-----------------+
2 rows in set (Elapsed: 00:00:00.01)
【初】单表带limit排序
带limit的排序,在GBase数据库里面,采用的是在每个节点先排序并返回limit的结果集到汇总表,然后汇总表再次做一次order返回最终结果,同样是2步:
第00步。
- MOTION:GATHER 结果发给汇总节点
- OPERATION:TABLE 全表;Order 排序; limit 返回有限结果集
- TABLE:T1[DIS],T1表是分布表, td[id], td表是Hash分布表。
- CONDITION:对Order是排序的条件; LIMIT是结果集行数
第01步
- MOTION:RESULT 结果发给调用方客户端
- OPERATION:Step 使用前一步的结果。 Order 排序; limit 返回有限结果集
- TABLE:T1[DIS],00 第一步汇总节点的表
- CONDITION:对Order排序,指排序的条件;LIMIT是结果集行数
gbase> explain select * from t1 order by id limit 1;
+----+----------+-----------+---------+-----------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | ORDER | | ORDER BY id ASC | |
| | | LIMIT | | LIMIT 1 | |
| 00 | [GATHER] | Table | t1[DIS] | | t1 |
| | | ORDER | | ORDER BY id ASC | |
| | | LIMIT | | LIMIT 1 | |
+----+----------+-----------+---------+-----------------+-----------------+
6 rows in set (Elapsed: 00:00:00.00)
gbase> explain select * from td order by id limit 1;
+----+----------+-----------+--------+-----------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+-----------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | ORDER | | ORDER BY id ASC | |
| | | LIMIT | | LIMIT 1 | |
| 00 | [GATHER] | Table | td[id] | | td |
| | | ORDER | | ORDER BY id ASC | |
| | | LIMIT | | LIMIT 1 | |
+----+----------+-----------+--------+-----------------+-----------------+
6 rows in set (Elapsed: 00:00:00.00)
【初】单表全部聚合GROUP
随机分布表
都是先做重分布[REDIST]到临时表,然后在临时表里做做狗的group操作并返回。
- 00:根据id列进行本地GROUP聚合后,将结果REDIST重分布到临时表
- 01:采用00步的临时表,进行二次GROUP聚合,并返回结果[RESULT}
gbase> explain select id,count(*) from t1 group by id;
+----+--------------+-----------+---------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+-----------+---------+-------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | GROUP | | GROUP BY id | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | t1 |
| | | GROUP | | GROUP BY id | |
+----+--------------+-----------+---------+-------------+-----------------+
4 rows in set (Elapsed: 00:00:00.00)
Hash分布表
聚合列不是分布列
执行计划和随机分布表是一样的。
gbase> explain select name,count(*) from td group by name;
+----+----------------+-----------+--------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------------+-----------+--------+---------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | GROUP | | GROUP BY name | |
| 00 | [REDIST(name)] | Table | td[id] | | td |
| | | GROUP | | GROUP BY name | |
+----+----------------+-----------+--------+---------------+-----------------+
4 rows in set (Elapsed: 00:00:00.01)
聚合列包含分布列
可以看到,因为聚合列包含了Hash分布列,和分布列有关的数据都在同一个节点上,各个节点各自做group,然后返回结果就可以了。
gbase> explain select id,count(*) from td group by id;
+----+----------+-----------+--------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+-------------+-----------------+
| 00 | [RESULT] | Table | td[id] | | td |
| | | GROUP | | GROUP BY id | |
+----+----------+-----------+--------+-------------+-----------------+
2 rows in set (Elapsed: 00:00:00.01)
复制表
与聚合列包含Hash分布表的分布列一样,都是一步出结果,不需要节点间拉数据。
gbase> explain select id,count(*) from tr group by id;
+----+----------+-----------+---------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-------------+-----------------+
| 00 | [RESULT] | Table | tr[REP] | | tr |
| | | GROUP | | GROUP BY id | |
+----+----------+-----------+---------+-------------+-----------------+
2 rows in set (Elapsed: 00:00:00.00)
【中】TOPN带排序和有限结果的的聚合
这个场景数据最常见的TOPN场景,按照聚合的数据排序,并返回有限的部分数据,比如人数最多的省份前10名。
随机分布表
首先还是要按照聚合列做重分布,然后再做各自的有限结果集的排序,并汇总到一个节点,最后做二次有限结果集的排序并返回结果。
- 00:按照聚合列id,本地聚合后,进行重分布(REDIST)
- 01:使用00步骤的表,做本地的有限结果集的排序(order limit),结果放到汇总表[GATHER]
- 02:使用01的汇总表,做第二次有限结果集的排序(order limit),并返回结果到调用端[RESULT]
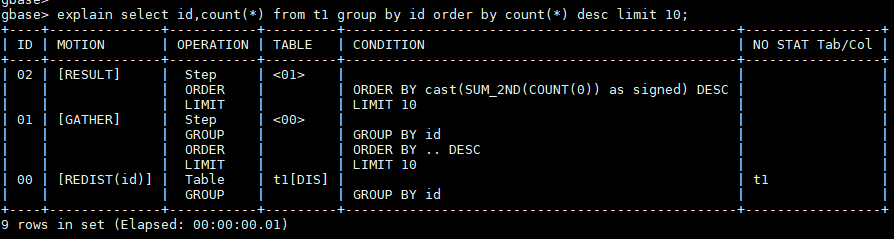
gbase> explain select id,count(*) from t1 group by id order by count(*) desc limit 10;
+----+--------------+-----------+---------+-------------------------------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+-----------+---------+-------------------------------------------------+-----------------+
| 02 | [RESULT] | Step | <01> | | |
| | | ORDER | | ORDER BY cast(SUM_2ND(COUNT(0)) as signed) DESC | |
| | | LIMIT | | LIMIT 10 | |
| 01 | [GATHER] | Step | <00> | | |
| | | GROUP | | GROUP BY id | |
| | | ORDER | | ORDER BY .. DESC | |
| | | LIMIT | | LIMIT 10 | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | t1 |
| | | GROUP | | GROUP BY id | |
+----+--------------+-----------+---------+-------------------------------------------------+-----------------+
9 rows in set (Elapsed: 00:00:00.00)
Hash分布表
聚合列不包含Hash分布列
则和随机分布表一样。
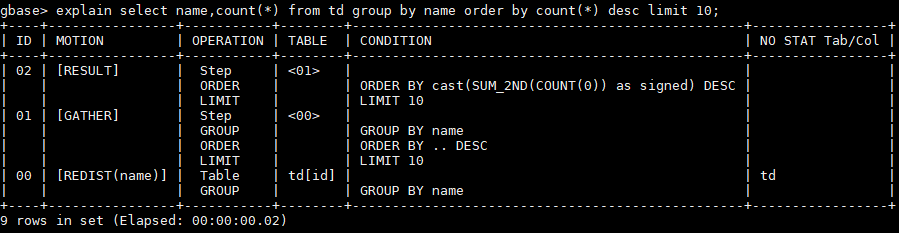
gbase> explain select name,count(*) from td group by name order by count(*) desc limit 10;
+----+----------------+-----------+--------+-------------------------------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------------+-----------+--------+-------------------------------------------------+-----------------+
| 02 | [RESULT] | Step | <01> | | |
| | | ORDER | | ORDER BY cast(SUM_2ND(COUNT(0)) as signed) DESC | |
| | | LIMIT | | LIMIT 10 | |
| 01 | [GATHER] | Step | <00> | | |
| | | GROUP | | GROUP BY name | |
| | | ORDER | | ORDER BY .. DESC | |
| | | LIMIT | | LIMIT 10 | |
| 00 | [REDIST(name)] | Table | td[id] | | td |
| | | GROUP | | GROUP BY name | |
+----+----------------+-----------+--------+-------------------------------------------------+-----------------+
9 rows in set (Elapsed: 00:00:00.02)
聚合列包含Hash分布列
则省掉了重分布步骤。
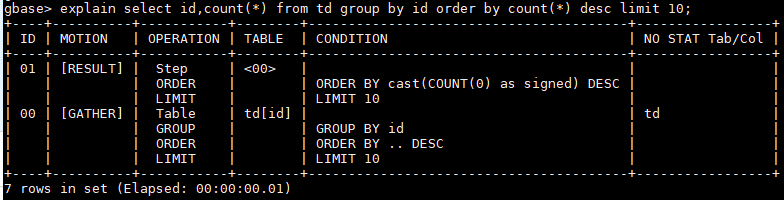
- 00: 本地做分组,并返回有限排序结果(order limit), 结果发到汇总表[GATHER]
- 01:采用00的汇总表,做二次有限结果集排序,并返回调用端[RESULT]
gbase> explain select id,count(*) from td group by id order by count(*) desc limit 10;
+----+----------+-----------+--------+----------------------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+--------+----------------------------------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | ORDER | | ORDER BY cast(COUNT(0) as signed) DESC | |
| | | LIMIT | | LIMIT 10 | |
| 00 | [GATHER] | Table | td[id] | | td |
| | | GROUP | | GROUP BY id | |
| | | ORDER | | ORDER BY .. DESC | |
| | | LIMIT | | LIMIT 10 | |
+----+----------+-----------+--------+----------------------------------------+-----------------+
7 rows in set (Elapsed: 00:00:00.01)
复制表
复制表都是一步直接出结果返回调用端。
gbase> explain select id,count(*) from tr group by id order by count(*) desc limit 10;
+----+----------+-----------+---------+------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+------------------+-----------------+
| 00 | [RESULT] | Table | tr[REP] | | tr |
| | | GROUP | | GROUP BY id | |
| | | ORDER | | ORDER BY .. DESC | |
| | | LIMIT | | LIMIT 10 | |
+----+----------+-----------+---------+------------------+-----------------+
4 rows in set (Elapsed: 00:00:00.01)
【初】UNION操作
每个节点各自做union去重,然后发送到汇总表。
2个随机分布表做union
- 00:t1和td做union去重,发送到汇总表[GATHER]
- 01:采用00的汇总表,再次去重(distinct)并返回[RESULT]
gbase> explain select id from t1 union select id from td;
+----+----------+-----------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | AGG | | | |
| 00 | [GATHER] | Table | t1[DIS] | | t1 |
| | | UNION | | | td |
| | | Table | td[id] | | |
+----+----------+-----------+---------+-----------+-----------------+
5 rows in set (Elapsed: 00:00:00.01)
2个Hash分布表做union
直接本地union即可,结果返回。
gbase> explain select * from td union select * from td_2;
+----+----------+-----------+----------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+----------+-----------+-----------------+
| 00 | [RESULT] | Table | td[id] | | td |
| | | UNION | | | td_2 |
| | | Table | td_2[id] | | |
+----+----------+-----------+----------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
1个Hash和1个随机分布表union
各节点分别做union,并将结果发送到汇总表,最后在汇总表做去重。
gbase> explain select * from t1 union select * from td;
+----+----------+-----------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | AGG | | | |
| 00 | [GATHER] | Table | t1[DIS] | | t1 |
| | | UNION | | | td |
| | | Table | td[id] | | |
+----+----------+-----------+---------+-----------+-----------------+
5 rows in set (Elapsed: 00:00:00.00)
【中】带单纯count(*)的union
union操作本身有去重功能,所以需要将每个参与的表都各自聚合后,再union去重,发送到汇总表,最后再次汇总三步;
- 00:t1表聚合,然后发到汇总表[GATHER]
- 01:td表聚合,然后发到汇总表[GATHER]
- 02:用00的表和01的表再次聚合并返回[RESULT]
gbase> explain select count(*) from t1 union select count(*) from td;
+----+----------+-----------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+---------+-----------+-----------------+
| 02 | [RESULT] | Step | <00> | | |
| | | AGG | | | |
| | | UNION | | | |
| | | Step | <01> | | |
| | | AGG | | | |
| 01 | [GATHER] | Table | td[id] | | |
| | | AGG | | | |
| 00 | [GATHER] | Table | t1[DIS] | | t1 |
| | | AGG | | | td |
+----+----------+-----------+---------+-----------+-----------------+
9 rows in set (Elapsed: 00:00:00.00)
【中】带聚合GROUP的union
本例也是一个多个操作合并的例子,也是常见操作。
2个随机分布表聚合结果的union。
- 00:t1表聚合后分发到Hash分布表[REDIST]
- 01:t1_2表聚合后分发到Hash分布表[REDIST]
- 02:00的Hash分布表和01的Hash分布表,再次做聚合GROUP并union 操作,结果发送客户端[RESULT]
gbase> explain select id,count(*) from t1 group by id union all select id,count(*) from t1_2 group by id;
+----+--------------+------------+-----------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+------------+-----------+-------------+-----------------+
gbase> explain select id,count(*) from t1 group by id union select id,count(*) from t1_2 group by id;
+----+--------------+-----------+-----------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+-----------+-----------+-------------+-----------------+
| 02 | [RESULT] | Step | <00> | | |
| | | GROUP | | GROUP BY id | |
| | | UNION | | | |
| | | Step | <01> | | |
| | | GROUP | | GROUP BY id | |
| 01 | [REDIST(id)] | Table | t1_2[DIS] | | |
| | | GROUP | | GROUP BY id | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | t1 |
| | | GROUP | | GROUP BY id | t1_2 |
+----+--------------+-----------+-----------+-------------+-----------------+
9 rows in set (Elapsed: 00:00:00.01)
2个Hash分布表聚合包含Hash分布列的union
因为2个表都是Hash分布表且包含在聚合列内,所以各节点分别做聚合和union操作后,直接返回即可。
gbase> explain select id,count(*) from td group by id union select id,count(*) from td_2 group by id;
+----+----------+-----------+----------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-----------+----------+-------------+-----------------+
| 00 | [RESULT] | Table | td[id] | | td |
| | | GROUP | | GROUP BY id | td_2 |
| | | UNION | | | |
| | | Table | td_2[id] | | |
| | | GROUP | | GROUP BY id | |
+----+----------+-----------+----------+-------------+-----------------+
5 rows in set (Elapsed: 00:00:00.00)
随机分布表和Hash分布表包含在聚合列的union
根据全面介绍,随机分布表将先做聚合后的重分布,然后再与Hash分布表做本地的二次聚合和union。
- 00:t1随机分布表做聚合,然后发送到Hash分布表
- 01:使用00的Hash分布表,与Hash分布表td做聚合和union操作,然后返回[RESULT]
gbase> explain select id,count(*) from t1 group by id union select id,count(*) from td group by id;
+----+--------------+-----------+---------+-------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+-----------+---------+-------------+-----------------+
| 01 | [RESULT] | Step | <00> | | |
| | | GROUP | | GROUP BY id | |
| | | UNION | | | |
| | | Table | td[id] | | |
| | | GROUP | | GROUP BY id | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | t1 |
| | | GROUP | | GROUP BY id | td |
+----+--------------+-----------+---------+-------------+-----------------+
7 rows in set (Elapsed: 00:00:00.04)【初】UNION ALL 操作
union all不需要去重,执行计划明显简单了很多。全部都是各节点做union all, 然后返回即可。
gbase> explain select * from t1 union all select * from t1_2;
+----+----------+------------+-----------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+------------+-----------+-----------+-----------------+
| 00 | [RESULT] | Table | t1[DIS] | | t1 |
| | | UNION ALL | | | t1_2 |
| | | Table | t1_2[DIS] | | |
+----+----------+------------+-----------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
gbase> explain select * from t1 union all select * from td;
+----+----------+------------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+------------+---------+-----------+-----------------+
| 00 | [RESULT] | Table | t1[DIS] | | t1 |
| | | UNION ALL | | | td |
| | | Table | td[id] | | |
+----+----------+------------+---------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
gbase> explain select * from td union all select * from td_2;
+----+----------+------------+----------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+------------+----------+-----------+-----------------+
| 00 | [RESULT] | Table | td[id] | | td |
| | | UNION ALL | | | td_2 |
| | | Table | td_2[id] | | |
+----+----------+------------+----------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.00)
【中】2表join操作
Hash分布表且join列为Hash分布列
因为Hash分布列也是Join的条件列(包含在JOIN条件中即可,无需唯一),无论哪种join,都是本地运行,然后返回结果即可。
gbase> explain select * from td left join td_2 on td.id=td_2.id;
+----+----------+------------+----------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+------------+----------+-----------+-----------------+
| 00 | [RESULT] | LEFT JOIN | | (id = id) | td |
| | | Table | td[id] | | |
| | | Table | td_2[id] | | |
+----+----------+------------+----------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.00)
gbase> explain select * from td right join td_2 on td.id=td_2.id;
+----+----------+------------+----------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+------------+----------+-----------+-----------------+
| 00 | [RESULT] | LEFT JOIN | | (id = id) | td_2 |
| | | Table | td_2[id] | | |
| | | Table | td[id] | | |
+----+----------+------------+----------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.00)
gbase> explain select * from td inner join td_2 on td.id=td_2.id;
+----+----------+-------------+----------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------+-------------+----------+-----------+-----------------+
| 00 | [RESULT] | INNER JOIN | | (id = id) | td_2 |
| | | Table | td_2[id] | | |
| | | Table | td[id] | | |
+----+----------+-------------+----------+-----------+-----------------+
3 rows in set (Elapsed: 00:00:00.01)
Hash分布大表和随机分布大表JOIN
大表指数据量超过参数的表,该参数通过gcluster_hash_redist_threshold_row设置,也就是如果小于这个数值,是可能被拉成复制表的。对各种JOIIN类型无区别。
- 00:随机分布表t1根据id进行Hash重分布。
- 01:使用00的结果表,与Hash分布表td进行本地join,然后返回结果。
gbase> explain select * from t1 left join td on t1.id=td.id;
+----+--------------+------------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+------------+---------+-----------+-----------------+
| 01 | [RESULT] | LEFT JOIN | | (id = id) | |
| | | Step | <00> | | |
| | | Table | td[id] | | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | t1 |
+----+--------------+------------+---------+-----------+-----------------+
4 rows in set (Elapsed: 00:00:00.64)
gbase> explain select * from t1 right join td on t1.id=td.id;
+----+--------------+------------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+------------+---------+-----------+-----------------+
| 01 | [RESULT] | LEFT JOIN | | (id = id) | |
| | | Table | td[id] | | |
| | | Step | <00> | | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | td |
+----+--------------+------------+---------+-----------+-----------------+
4 rows in set (Elapsed: 00:00:00.79)
gbase> explain select * from t1 inner join td on t1.id=td.id;
+----+--------------+-------------+---------+-----------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+--------------+-------------+---------+-----------+-----------------+
| 01 | [RESULT] | INNER JOIN | | (id = id) | |
| | | Step | <00> | | |
| | | Table | td[id] | | |
| 00 | [REDIST(id)] | Table | t1[DIS] | | t1 |
+----+--------------+-------------+---------+-----------+-----------------+
4 rows in set (Elapsed: 00:00:00.25)
2个大的随机分布表做Join
如下例子采用name列做join条件,需要先将2个表分别做动态重分布,然后再本地join返回。各种JOIN类型没区别。
- 00:td虽然是Hash分布表但JOIN列不是Hash分布列,根据name列做动态重分布。
- 01:t1是随机分布表,根据name做动态重分布
- 02:采用00和01的表,做本地join并返回结果
gbase> explain select * from t1 left join td on t1.name=td.name;
+----+----------------+------------+---------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------------+------------+---------+---------------+-----------------+
| 02 | [RESULT] | LEFT JOIN | | (name = name) | |
| | | Step | <00> | | |
| | | Step | <01> | | |
| 01 | [REDIST(name)] | Table | td[id] | | |
| 00 | [REDIST(name)] | Table | t1[DIS] | | t1 |
+----+----------------+------------+---------+---------------+-----------------+
5 rows in set (Elapsed: 00:00:00.89)
gbase> explain select * from t1 right join td on t1.name=td.name;
+----+----------------+------------+---------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------------+------------+---------+---------------+-----------------+
| 02 | [RESULT] | LEFT JOIN | | (name = name) | |
| | | Step | <00> | | |
| | | Step | <01> | | |
| 01 | [REDIST(name)] | Table | t1[DIS] | | |
| 00 | [REDIST(name)] | Table | td[id] | | td |
+----+----------------+------------+---------+---------------+-----------------+
5 rows in set (Elapsed: 00:00:00.37)
gbase> explain select * from t1 inner join td on t1.name=td.name;
+----+----------------+-------------+---------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------------+-------------+---------+---------------+-----------------+
| 02 | [RESULT] | INNER JOIN | | (name = name) | |
| | | Step | <00> | | |
| | | Step | <01> | | |
| 01 | [REDIST(name)] | Table | td[id] | | |
| 00 | [REDIST(name)] | Table | t1[DIS] | | t1 |
+----+----------------+-------------+---------+---------------+-----------------+
5 rows in set (Elapsed: 00:00:00.50)
大的随机分布表和小的随机分布表做JOIN
因为时大小表,区分JOIN类型。
LEFT JOIN 小表拉复制表
因为t1_2只有1000行,而t1有3300万,所以小表拉了复制表。
- 00:t1_2小表拉了复制表[BROADCAST]
- 01:采用大的随机分布表t1和00的复制表做JOIN并返回结果
gbase> explain select * from t1 left join t1_2 on t1.name=t1_2.name;
+----+-------------+------------+-----------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+-------------+------------+-----------+---------------+-----------------+
| 01 | [RESULT] | LEFT JOIN | | (name = name) | |
| | | Table | t1[DIS] | | |
| | | Step | <00> | | |
| 00 | [BROADCAST] | Table | t1_2[DIS] | | t1 |
+----+-------------+------------+-----------+---------------+-----------------+
4 rows in set (Elapsed: 00:00:00.77)
inner join也是小表拉复制表
gbase> explain select * from t1 inner join t1_2 on t1.name=t1_2.name;
+----+-------------+-------------+-----------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+-------------+-------------+-----------+---------------+-----------------+
| 01 | [RESULT] | INNER JOIN | | (name = name) | |
| | | Step | <00> | | |
| | | Table | t1[DIS] | | |
| 00 | [BROADCAST] | Table | t1_2[DIS] | | t1_2 |
+----+-------------+-------------+-----------+---------------+-----------------+
4 rows in set (Elapsed: 00:00:00.57)
right join 大表拉了复制表
从执行计划看,3300万的t1表被拉了复制表[BROADCAST],在多数情况下,这个结果并不符合最优的结果,就算是right,也是可以小表拉复制表的。后面的例子给了解决方案。
- 00:大表t1拉了复制表【BROADCAST]
- 01:00的复制表和t1_2的小表做JOIN,并返回结果
gbase> explain select * from t1 right join t1_2 on t1.name=t1_2.name;
+----+-------------+------------+-----------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+-------------+------------+-----------+---------------+-----------------+
| 01 | [RESULT] | LEFT JOIN | | (name = name) | |
| | | Table | t1_2[DIS] | | |
| | | Step | <00> | | |
| 00 | [BROADCAST] | Table | t1[DIS] | | t1_2 |
+----+-------------+------------+-----------+---------------+-----------------+
4 rows in set (Elapsed: 00:00:00.68)
right join通过调整参数,大小表都做了hash重分布
通过调整参数,被join的表,超过指定参数值(3300万超过了1万),则被join表拉了分布表,而不是分布表。从本例看,主表没有拉复制表,而是全部拉了Hash分布表。参数含义,请参考 GBase 8a性能优化案例
- 00:小表t1_2根据name列做了hash重分布[REDIST]
- 01:大表t1根据name列做了Hash重分布[REDIST]
- 02:使用00和01做了Hash分布的表,做本地join并返回结果。
gbase> set gcluster_hash_redist_threshold_row=10000;
Query OK, 0 rows affected (Elapsed: 00:00:00.02)
gbase> explain select * from t1 right join t1_2 on t1.name=t1_2.name;
+----+----------------+------------+-----------+---------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+----------------+------------+-----------+---------------+-----------------+
| 02 | [RESULT] | LEFT JOIN | | (name = name) | |
| | | Step | <00> | | |
| | | Step | <01> | | |
| 01 | [REDIST(name)] | Table | t1[DIS] | | |
| 00 | [REDIST(name)] | Table | t1_2[DIS] | | t1_2 |
+----+----------------+------------+-----------+---------------+-----------------+
5 rows in set (Elapsed: 00:00:00.92)
【高】当select列特别多时的带limit 的排序优化。
如果查询列非常多,节点也多,特别是offset也多(比如节点上一共100万行,limit 490000,10 这种情形,每个节点就要返回接近一半数据到汇总节点),那么在GATHER阶段,就会有大量的数据被发送到汇总节点,再次排序后,绝大部分数据都将被抛弃,造成了资源浪费。在这种情况下,采用了类似延迟物化的方式:先把本地排序后的必须列和行号rowid发送到汇总节点,在汇总节点排序拿到最终结果后,再返回原始节点,按照rowid获得其它的列,这样就减少了数据资源的浪费。
通过gcluster_order_by_limit_offset_optimize参数,可以改变执行计划。设置为1则启用如下的执行计划。默认是0。
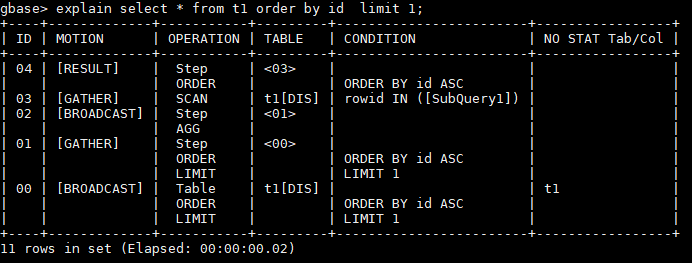
- 00:将本地排序的数据,放到一个【复制表 BROADCAST】里,其中包含了行号和参与排序的必须列。
- 01:将复制表排序,拿到符合返回条件的结果集。
- 02:再将符合条件的结果,拉成复制表
- 03:从各个节点,返回符合条件的指定rowid的所返回所有列的数据到汇总节点,注意其中用的是子查询 rowid in
- 04:包含所有列的表进行排序,返回结果给调用端。
gbase> set gcluster_order_by_limit_offset_optimize=1;
Query OK, 0 rows affected (Elapsed: 00:00:00.00)
gbase> explain select * from t1 order by id limit 1;
+----+-------------+-----------+---------+------------------------+-----------------+
| ID | MOTION | OPERATION | TABLE | CONDITION | NO STAT Tab/Col |
+----+-------------+-----------+---------+------------------------+-----------------+
| 04 | [RESULT] | Step | <03> | | |
| | | ORDER | | ORDER BY id ASC | |
| 03 | [GATHER] | SCAN | t1[DIS] | rowid IN ([SubQuery1]) | |
| 02 | [BROADCAST] | Step | <01> | | |
| | | AGG | | | |
| 01 | [GATHER] | Step | <00> | | |
| | | ORDER | | ORDER BY id ASC | |
| | | LIMIT | | LIMIT 1 | |
| 00 | [BROADCAST] | Table | t1[DIS] | | t1 |
| | | ORDER | | ORDER BY id ASC | |
| | | LIMIT | | LIMIT 1 | |
+----+-------------+-----------+---------+------------------------+-----------------+
11 rows in set (Elapsed: 00:00:00.02)