本文介绍GBaase 8a数据库集群的执行计划功能。包括语法以及一些常见场景的执行计划分析。
目录导航
参考
如需要从简单到复杂的SQL执行计划学习,请参考
语法
explain/desc [extanded/partitions] select …
- explain只能显示sql select部分的执行计划
- 标准输出为explain,加extanded/partitions时可以以扩展方式和树形方式输出执行计划信息
- 支持with … as select …类型的CTE(Common Table Expression)公用表表达式语法,需要集群层设置_t_gcluster_support_cte=1
说明
标准输出界面及主要组成部分
显示界面主要组成部分:
- ID:SQL执行步骤,顺序从下向上
- MOTION:某个步骤的结果处理方式
- OPERATION:某个步骤内的具体执行操作
- TABLE:某个operation涉及的表
- CONDITION:某个operation操作涉及的条件
1234
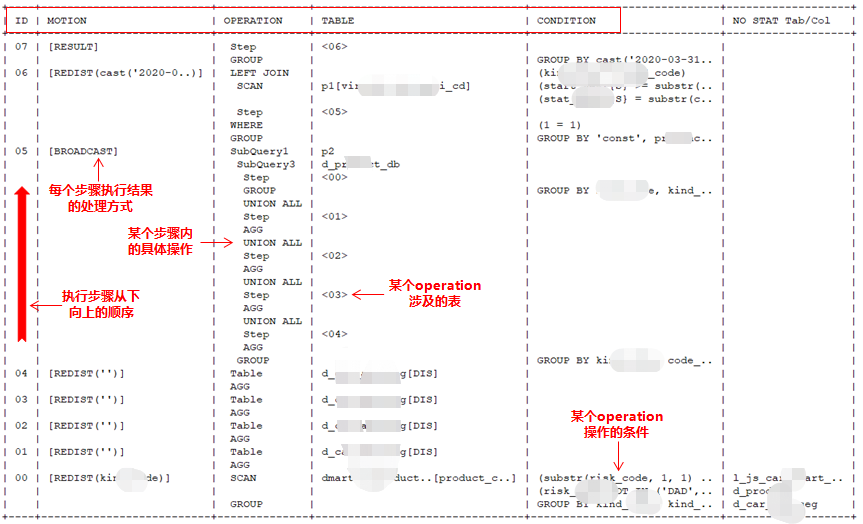
执行计划每个列的含义
| 显示列 | 具体释义 |
| ID | 执行计划的步骤,从00开始,从显示界面的下方向上执行。 |
| MOTION | 某个步骤的结果集处理方式,具体包括如下: RESULT:结果发送到客户端,一般为执行计划的最后一步; GATHER:结果发送到汇总节点,一般在sort或聚集函数操作前; REDIST(…):结果HASH重分布,括号中为计算HASH的列,如果超长则截断为两个点; NO REDIST:结果直接保存到对应的数据分片,不进行重分布; BROADCAST:结果拉复制表; RAND REDIST:结果随机分布到所有节点; SCALAR N:结果为标量,N为标量子查询的编号,如果条件中有引用,则使用&xNx&方式引用。 |
| OPERATION | 某个步骤的具体操作: SCAN:单表扫描,并使用条件过滤数据; Table:单表,没有过滤条件; SubQueryN:子查询,N为自动编号; Step:使用前一个Step的结果; INNER/LEFT/FULL JOIN:连接操作; WHERE:子查询的WHERE条件; GROUP:分组操作; ORDER:排序操作; LIMIT:计算LIMIT,OFFSET; AGG:distinct,聚集操作; UNION/UNION ALL/MINUS/INTERSECT:UNION操作。 |
| TABLE | 某个操作OPERATION涉及的表,只显示别名和属性,超长截断为两个点: HASH分布表:中括号中显示HASH列; 复制表:显示[REP]; 随机分布表:显示[DIS]; 子查询:OPERATION列显示SubQueryN,其中N为数字,用来区分不同的子查询; 某个步骤的结果集:OPERATION列显示为Step,本列显示为<N>其中N为ID列中的对应值,表示该步骤的结果。 |
| CONDITION | 显示某个操作OPERATION的条件: SCAN操作单表过滤条件; JOIN操作的连接条件; GROUP BY操作涉及列或表达式; ORDER BY操作涉及列或表达式; LIMIT OFFSET内容。 |
步骤内的执行计划缩进显示
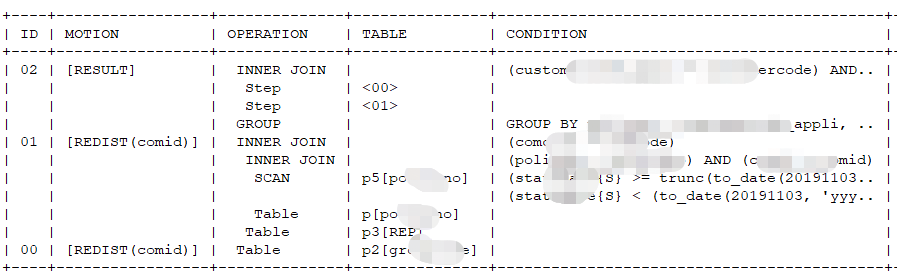
样例1
SQL语句
一个内层多表LEFT JOIN,外层group的SQL。其中主表T1和T2表(OVIEW.ods_XXXX)是一个视图。

执行计划

解析
Step00
- Step00在内存中物化视图T2表
- T2表是视图,GBase中转换为子查询(SubQuery4)
- T2表上无单表条件,因此视图基表ods_XXXX的OPXXXX是Table,表示单表且无过滤条件
- MOTION中有REDIST(maXXX)表明ods_XXXX表需要按照maiXXX进行一次动态重分布,ods_XXXX表本身的分布列是id,重分布的原因是和t1表的关联列是maiXXX
Step01
- Step01是T1表子查询内部的基表物化步骤,基表为ods_XXXXX
- CONDITION中Where条件为CAST(INDATE AS DATE) <= CAST(‘2020-03-31’ AS DATE),GROUP BY条件为maXXXX
- MOTION中有REDIST(maXXXX)表明odsXXXX需要按照mainno进行重分布, odsXXXXX表本身的分布列是id,重分布原因是T1表和T2表join的列是maXXXXX
step02
- Step02是执行step01和step00的结果inner join的步骤,即T1 inner join T2的步骤
- T1表是视图,因此GBase转成子查询SubQuery2
- T1、T2表的join CONDITION为T1.MAXXX = T2.MAXXXX AND CAST(T1.INDATE AS DATE) = CAST(T2.INDATE AS DATE)
- MOTION中有REDIST(userXXXX)表明step02步骤的结果集需要按照userXXXX进行重分布,step02结果集的分布列是maXXXX,重分布原因是和T3表join的列是userXXXX
Step03
- Step03是执行step02的结果集和T3 left join的步骤
- T3是视图,因此OPERATION为子查询SubQuery5,T3表上无单表条件,因此视图基表ods_XXXXr的OPERATION是Table,表示单表且无过滤条件
- Left join的条件CONDITION为T2.USERXXXX = T3.USERXXXX,这一步的join因step02的结果集已经按useXXXX进行过重分布,T3表本身的分布列就是useXXXX,因此可以走静态hash join执行计划
- MOTION中有REDIST(maXXXX)表明step03的结果集需要按照mainno列进行一次重分布,原因是step04中的join条件是T1.MAXXXX = T4.CLXXXX,且T4表的分布列是CLXXXX
Step04
- Step04是执行step03结果集和T4表left join的步骤
- 根据缩进格式,首先执行stop03结果集<03>和T4表的left join,然后执行where条件过滤,最后执行GROUP BY
- T4表是视图,所以GBase转为子查询SubQuery6,基表clm_XXXX为单表没有单表条件,因此OPERATION为Table
- 这一步的结果集<03>的分布列本身为maXXXX(由step03中的MOTION重分布得来),T4表的分布列是claim_XXXX,left join的CONDITION条件为maXXXX = claim_XXXX,执行计划为静态hash join
- 子查询的结果为TT表,WHERE条件为TT.COXXXX <> TT.ACXXXX AND CAST(TT>TURXXXX AS DATE) <= CAST(‘2020-03-31’ AS DATE)
- GROUP BY列为CLAXXXX, TURXXXX,包括了子查询tt的hash分布列CLAXXXXO,因此满足静态hash group by执行计划条件
- Step04的MOTION RESULT意为将最终发送执行结果