在某个项目里,有接近20个表参与left join,但每个表命中的数据量都很少,不超过6万行。在运行中,发现最耗时的阶段只有1个节点在运行,且产生了大量的临时中间文件。查看执行日志确认所有数据表都别拉成了复制表,最后在1个节点上运行。通过调整gcluster_hash_redistribute_join_optimize参数,强行将主表,虽然数据量也不多,拉成分布表,性能有1倍以上的提升。预计节点越多,性能提升越多。
目录导航
参考
参数
gcluster_hash_redistribute_join_optimize
含义
是否启用Hash重分布的JOIN模式。默认值是2。
参数=0拉复制表
参数=1一直使用。在两个分布表进行等值JOIN运算时,
将把其中一个表的数据根据连接条件列的值进行哈希重分布。
然后,利用各个运算节点上重分布后的临时表和另一个进行JOIN运算。
这样,各节点的运算结果直接汇总即可得到最终结果。
这种策略可以免于将其中一个分布表在所有运算节点上拉成复制表,而是每个运算节点只需接收这个表的一部分数据。
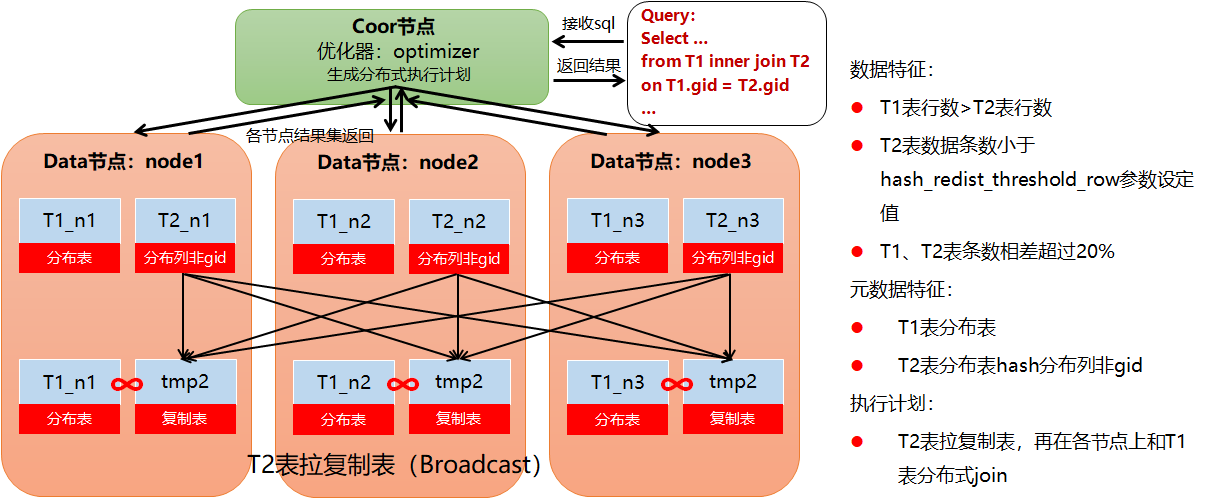
参数=2由规则决定:两表的尺寸相差不超过20%时,使用哈希重分布JOIN;否则不使用。
说明
由于数据量很少,且很接近,最终执行计划是将表都拉成了复制表,导致在逐级join后在单个节点产生了大量的临时中间文件。
通过调整参数为1,将主表拉成了分布表,最终所有计算节点全部能参与运算,提升了性能。
辅助参数
参数1
gcluster_hash_redist_threshold_row
说明1
当该值不为 0 时,若小表拉表的数据行数大于该值,进行 HASH 重分布 JOIN。
该参数的默认值是 0。
该参数配合gcluster_hash_redistribute_join_optimize的参数值2使用。
样例
小于参数走复制表
如果大于参数值,则走重分布
参数2
gcluster_hash_redistribute_join_optimize
说明2
是否启用Hash重分布的JOIN模式。默认值是1。
参数=0禁用。
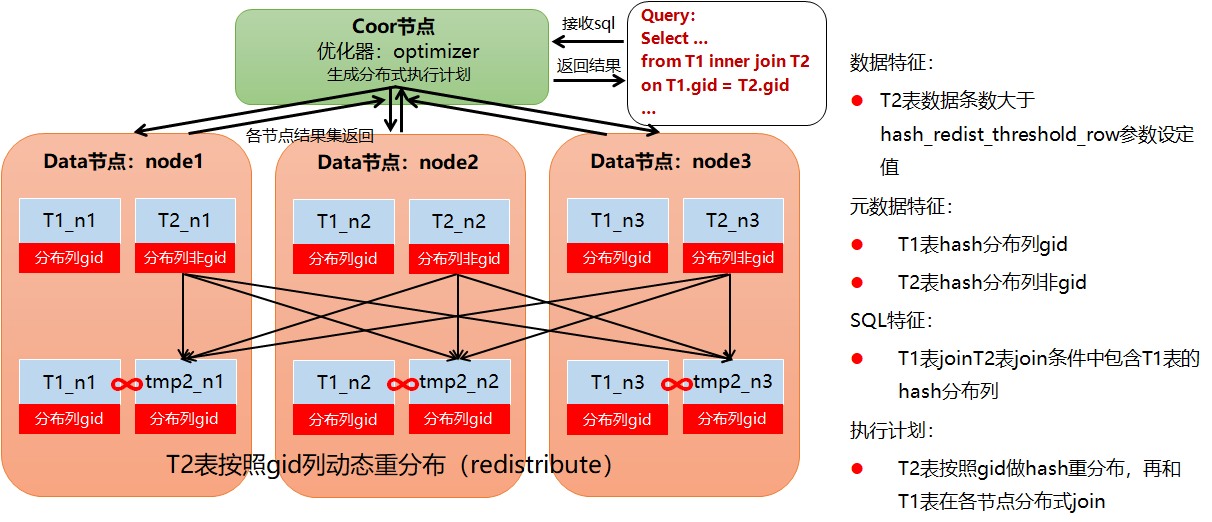
参数=1一直使用。在两个分布表进行等值JOIN运算时,将把其中一个表的数据根据连接条件列的值进行哈希重分布。
然后,利用各个运算节点上重分布后的临时表和另一个进行JOIN运算。这样,各节点的运算结果直接汇总即可得到最终结果。
这种策略可以免于将其中一个分布表在所有运算节点上拉成复制表,而是每个运算节点只需接收这个表的一部分数据。
参数=2由规则决定:两表的尺寸相差不超过20%时,使用哈希重分布JOIN;否则不使用。
参数3
gcluster_hash_redistribute_groupby_optimize
说明3
这个参数用于控制是否启用Hash重分布的GROUP BY模式。
参数=0禁用。
参数=1启用。进行分组(groupby)运算之前,将会把临时结果利用哈希算法重分布到各个运算节点,再由各个节点进行分组运算。由于数据在分到各个节点之前已经做了哈希,因此产生的结果直接汇总即可得到最终结果,不再需要由汇总节点再做一次分组。
该参数的默认值是1。
需要说明的是:当查询包含OLAP函数、ORDERBY、LIMIT时,无法使用本参数进行优化。
参数影响执行计划方式
| join场景 | gcluster_hash_redistribute_join_optimize 参数1 | gcluster_hash_redist_threshold_row 参数2 | 执行计划 |
| 两表均为分布表, join条件为两表hash分布列 | 2或1 | 无影响 | 直接本地进行join运算 走静态hash join执行计划, |
| 一表为分布表,一表为复制表 | 无影响 | 无影响 | 直接本地进行join运算 走分布表join复制表执行计划 |
| 两表均为分布表 join条件为其中一表hash分布列 | =2 根据参数2判断执行计划 =1 走执行计划1) =0 走执行计划2) | 参数1= 2,根据参数2的数值评估,如下: IF 小表条数 < gcluster_hash_redist_threshold_row and 大表和小表的条数差距超过20% Then 走执行计划2 Else 走执行计划1 END | 1)将非join列hash分布表按照join条件列动态重分布,走动态重分布hash join执行计划1 2)将较小的表拉成复制表,走拉复制表执行计划 |
| 两表为分布表, join条件非两表任意一表hash分布列 | =2 根据参数2判断执行计划 =1 走执行计划1) =0 走执行计划2) | 如参数1 = 2,根据参数2的数值评估,如下: IF 小表条数 < gcluster_hash_redist_threshold_row and 大表和小表的条数差距超过20% Then 走执行计划2 Else 走执行计划1 END | 1)将两个非join列hash分布表按照join条件列分别动态重分布,走动态重分布hash join 2)将较小的表拉成复制表,走拉小表拉复制表执行计划 |