GBase 8a在早期版本,如果出现大量的event,会出现性能急剧下降,一般出现在节点故障且长时间(15-90天都出现过)不能恢复的情况下。新版本改进了算法,本文测试了68万个ddlevent在整个期间的性能情况。
目录导航
环境
2节点本地虚拟机。1个管理节点,2个数据节点。人工将第二个节点关闭,模拟故障。
集群版本 8.6.2Build43R28
[root@rh6-1 ~]# gcadmin
CLUSTER STATE: ACTIVE
CLUSTER MODE: NORMAL
=================================================================
| GBASE COORDINATOR CLUSTER INFORMATION |
=================================================================
| NodeName | IpAddress |gcware |gcluster |DataState |
-----------------------------------------------------------------
| coordinator1 | 10.0.2.201 | OPEN | OPEN | 0 |
-----------------------------------------------------------------
================================================================
| GBASE DATA CLUSTER INFORMATION |
================================================================
|NodeName | IpAddress | gnode |syncserver |DataState |
----------------------------------------------------------------
| node1 | 10.0.2.201 | OPEN | OPEN | 0 |
----------------------------------------------------------------
| node2 | 10.0.2.202 | OFFLINE | | |
----------------------------------------------------------------
[root@rh6-1 ~]#
测试结果
[root@rh6-1 ~]# gcadmin showddlevent | head
Event count:16/642036
Event ID: 77601
ObjectName: testdb
Fail Node Copy:
------------------------------------------------------
Fail Data Copy:
------------------------------------------------------
NodeIP: 10.0.2.202 FAILURE
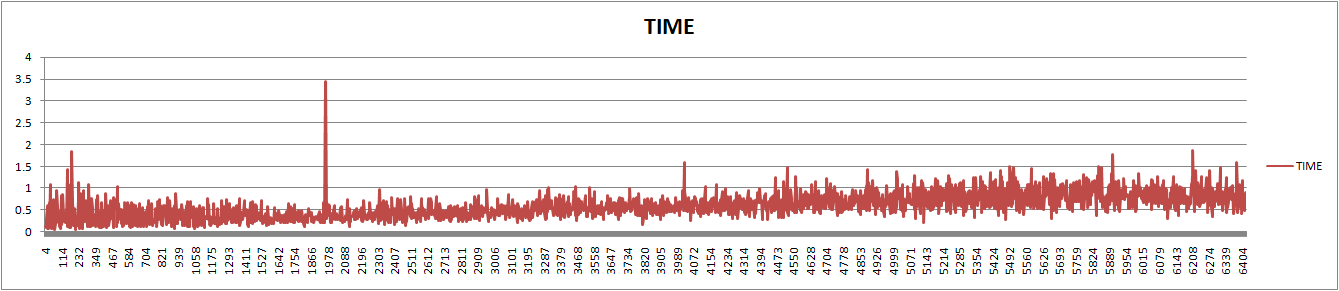
在整个测试期间,查询性能没有见到明显下降。整体还是在0.6-1秒左右。
测试脚本
考虑到inode问题,本例采用的是增加列,然后删除列的方案来模拟ddl故障。
for((i=1;i<=1000000;i++));
do
gncli -h10.0.2.201 -P5258 -e"alter table testdb.t_event_2 drop column id_$((${i}-1));alter table testdb.t_event_2 add column (id_$((${i})) int);"
done;
查询sql每隔10秒一次
while [ 2 -gt 1 ];
do
gcadmin showddlevent | grep -i count
gccli -e"select now(), count(*) from testdb.t1 where id between 1000 and 10000" -vvv
sleep 10
done;