本文介绍,通过GBase 8a数据库集群的执行日志,分析每一步的耗时来排查性能问题。
目录导航
参考
GBase 8a 执行计划Explain介绍
GBase 8a通过集群日志查看执行计划和每个阶段的整体耗时和各个节点的耗时做性能排查
作用
记录SQL的完整执行计划和过程,目前只包括select语句。根据trc日志,排查性能执行计划问题和性能问题。重点在数据节点上。
使用方法
使用集群客户端 gccli
gbase> set gbase_sql_trace=1;
gbase> set global gbase_sql_trace_level=3;
第一个参数是打开和关闭trc日志,可以是session级的。
第二个参数是日志级别,必须是global级别的。
执行SQL语句后,在gnode的log目录下生成trc结尾的日志。
使用样例
日志的名字里,包含了连接数据库的用户,时间等信息。一般人工开启都是比较新的trc就是。如果SQL复杂,可能包含多个trc。
gnode计算节点trc日志整体结构
如下是整体的结构,分为摘要区,SQL语句,整个执行过程,和汇总阶段。 其中执行阶段,包含了时间戳和资源情况。
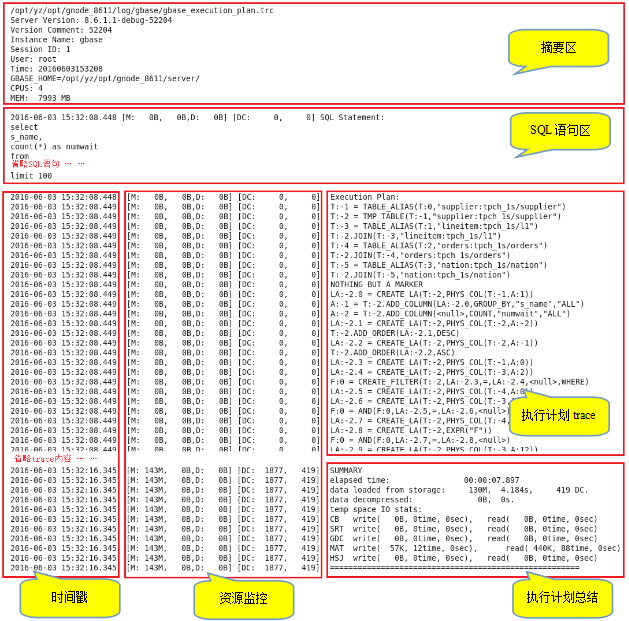
摘要区
摘要区trace主要内容包括:服务端信息、客户端连接信息、服务端系统环境信息等。并非每次查询都产生摘要trace,当某个Session首次写trace文件时会产生摘要区trace。
这部分,每个trc就生成一次。
/opt/yz/opt/gnode_8611/log/gbase/gbase_execution_plan.trc -- trace文件路径
Server Version: 8.6.1.1-debug-52204 -- gbased服务端版本号
Version Comment: 52204
Instance Name: gbase -- 实例名称
Session ID: 1 -- 连接Session ID
User: root -- 连接用户名
Time: 20160603153208 -- 时间戳
GBASE_HOME=/opt/yz/opt/gnode_8611/server/ -- GBASE_HOME环境变量值
CPUS: 4 -- CPU核数
MEM: 7993 MB -- 系统物理内存大小SQL语句区
注意,在gnode的都是分片的,一般带_n1等分片号。
如下是样例1,也是最常见的。
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] SQL Statement:
CREATE TABLE `gctmpdb`._tmp_2544806080_103_t8_1_1448416419_s AS SELECT /*192.168.174.151_103_8_2015-11-24_19:28:32*/ /*+ TID('56') */ `testdb.dr_a_iucs`.`callingnum` AS `tmp_gc_col_1` FROM `testdb`.`dr_a_iucs_n1` `testdb.dr_a_iucs` WHERE (`testdb.dr_a_iucs`.`callingnum` = '13075920555') LIMIT 0样例2,大体上差别不大,是扩容重分布时的trc日志。
2021-09-27 15:20:51.101 [M: 26G, 0B,D: 0B] [DC: 325, 121] [Memory Statistics (LOCAL)] PeakSize: 30.50MB, allocated: 30.50MB, used: 30.24MB, free: 262.85KB, peak_per_table: 27.00MB.
Query: SELECT * FROM "emsplus"."fact_ipdr_log_20210901_n48" LIMIT 100000000,100000000 TARGET INTO SERVER (content skipped)...
资源区
数据结构如下:[内存:数据堆,large堆,磁盘:临时表空间] [访问DC数:内存命中,磁盘访问]
[M:1.45G, 27M,D: 633K] [DC: 19006, 3899]
[M:1.45G, 41M,D: 633K] [DC: 19500, 3901]
[M:1.45G, 41M,D: 633K] [DC: 19500, 3901]
[M:1.50G, 54M,D: 633K] [DC: 19500, 4110]
[M:1.50G, 48M,D: 633K] [DC: 19500, 4110]
[M:1.50G, 48M,D: 633K] [DC: 19500, 4110]
[M:1.50G, 41M,D: 633K] [DC: 19500, 4111] - -- (1). 数据堆:data heap的使用状况,全局状态
- -- (2). Large堆: 算子buffer的使用情况, 全局状态
- -- (3). 临时表空间: session级,语句执行过程中占用的临时磁盘空间
- -- (4). 内存中访问DC总数 :session级 可以看出从内存缓冲中访问的DC总数
- -- (5). 磁盘中访问DC总数 :session级 可以看到从磁盘中访问的DC总数
执行计划汇总
其中执行总时间,是最要关注的,首要的排查目标是耗时最长的SQL。
SUMMARY –- 执行计划总结
elapsed time: 00:00:07.897 -- SQL执行时间
data loaded from storage: 130M, 4.184s, 419 DC.-- 总共从磁盘读了130MB (共419个DC)的数据,用时4.184s
data decompressed: 0B, 0s.-- 总共解压了0B数据,用时0s
temp space IO stats:-- 查询过程中临时表空间使用情况
CB write( 0B, 0time, 0sec), read( 0B, 0time, 0sec)-- 物化中间结果(读写大小, 读写请求次数,读写花费时间)
SRT write( 0B, 0time, 0sec), read( 0B, 0time, 0sec)-- 排序中间结果
GDC write( 0B, 0time, 0sec), read( 0B, 0time, 0sec)-- groupby distinct中间结果
MAT write( 57K, 12time, 0sec), read( 440K, 88time, 0sec)-- join中间结果
HSJ write( 0B, 0time, 0sec), read( 0B, 0time, 0sec)-- One-Pass Hash Join分片文件中间结果
======================================================执行详细部分
这部分最复杂,主要找到每个阶段耗时,并分析能否进行优化。
开始执行
显示涉及到的表,并命名为T0,T1等别名
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] Start Query Execution
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] Tables:
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] T0: testdb.dr_a_iucs(testdb.dr_a_iucs_n1), 6 rows, 1 DC
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] Condition Weight (non-join):
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] cnd(0): FALSE (0)智能扫描
涉及多个表,多个字段时,会分别扫描。只用到智能索引部分,所以一般耗时很少。
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] BEGIN Smart Scan
2015-11-24 19:28:32.049 [M: 8K, 0B,D: 0B] [DC: 0, 0] T0: total 1 DC, found 1 DC to scan(with 0 FULL DC).扫描
根据智能扫描的结果,将不完全符合条件的DC,做完整扫描。需要读取DC数据,解压后逐行扫描,耗时较长。
2015-11-24 19:28:32.050 [M: 8K, 0B,D: 0B] [DC: 0, 0] BEGIN Scan
2015-11-24 19:28:32.050 [M: 8K, 0B,D: 0B] [DC: 0, 0] T0: total 1 DC, found 0 DC after scan(with 0 FULL DC).
其它
根据执行的业务复杂度,会有不同的join, group, union 等等步骤,需要根据业务查看。
发送
将结果发送到目标接受端。一般是汇总表。
2015-11-24 19:28:32.050 [M: 8K, 0B,D: 0B] [DC: 0, 0] ResultSender: send 0 rows.
2015-11-24 19:28:32.050 [M: 8K, 0B,D: 0B] [DC: 0, 0] insert done.gcluster层的trc日志介绍
这个和gnode层的不同,主要是执行计划explain 的工作下发,有gnode负责具体执行。
[root@gbase_rh7_001 gcluster]# cat gcluster_root_4_20210930163246.trc
/opt/gbase/gcluster/log/gcluster/gcluster_root_4_20210930163246.trc
Server Version: 9.5.2.43.1df83ea1
Version Comment: 1df83ea1
Instance Name: gcluster
Session ID: 4
User: root
Time: 20210930163246
GBASE_HOME=/opt/gbase/gcluster/server/
CPUS: 4
MEM: 3790 MB
2021-09-30 16:32:46.445 before opt:select "vcname000001"."testdb"."t1"."id" AS "id",count(0) AS "count(*)" from "vcname000001"."testdb"."t1" group by "vcname000001"."testdb"."t1"."id" order by count(0) desc limit 10
2021-09-30 16:32:46.445 after opt:select "vcname000001"."testdb"."t1"."id" AS "id",count(0) AS "count(*)" from "vcname000001"."testdb"."t1" group by "vcname000001"."testdb"."t1"."id" order by count(0) desc limit 10
2021-09-30 16:32:46.448
-------------After all optimized modules -----------
Now the sql is : SELECT `vcname000001.testdb.t1`.`id` as `id`, cast(COUNT(0) as signed) as `count(*)` From `testdb`.`t1` `vcname000001.testdb.t1` GROUP BY `vcname000001.testdb.t1`.`id` ORDER BY cast(COUNT(0) as signed) DESC LIMIT 10
----------ALL nodes here:
--------------------------------------
nodeId = 1
nodeType = RELATION - Type: 2
Node Alias: t1
outerLevel = 0
prserveSubTree = FALSE
----- evaluate cost-----
RowSize = 1 Rows = 1 The cost = 0
-----Joins-----
-----Projections-----
`vcname000001.testdb.t1`.`id`
-----Conditions-----
--------------------------------------
==============================================
Join Tree:
vcname000001.testdb.t1
==============================================
vcname000001.testdb.t1
==============================================
vcname000001.testdb.t1{}
2021-09-30 16:32:46.532 elapsed time: 00:00:00.086
2021-09-30 16:32:46.532 Executor success.