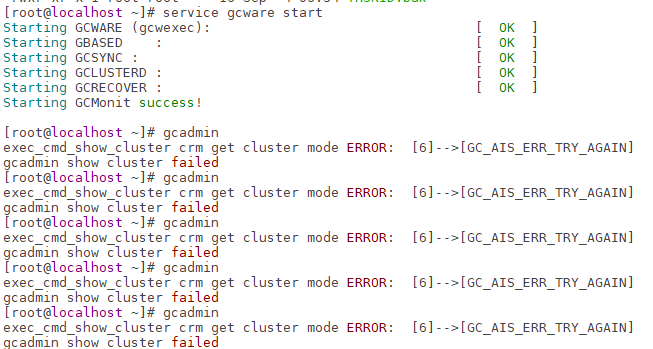
本文介绍GBase 8a数据库集群,其它节点全部正常,一台服务停止状态。而当这个节点服务启后,显示成功了,但输入gcadmin显示GC_AIS_ERR_TRY_AGAIN。原因是同步REDOLOG信息。
目录导航
现象
启动成功了,但输入gcadmin报错GC_AIS_ERR_TRY_AGAIN, 需要等待几秒到几分钟后才会正常。

一段时间后正常
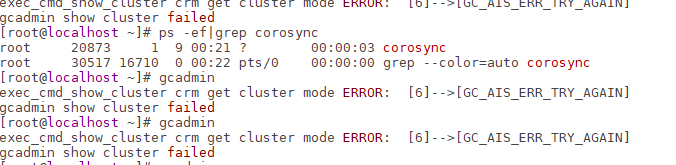
排查
查看corosync进程,存在,没有不断重启。
查看 corosync.log 发现如下信息一直在刷新:
Sep 05 00:22:21 corosync [corosy] persist_sync_finish leave 1
Sep 05 00:22:21 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]
Sep 05 00:22:22 corosync [CLM ] [DEBUG]: clm_sync_process [ENTER]
Sep 05 00:22:22 corosync [corosy] persist_sync_finish enter
Sep 05 00:22:22 corosync [corosy] persist_sync_finish leave 1
Sep 05 00:22:22 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]
Sep 05 00:22:23 corosync [CLM ] [DEBUG]: clm_sync_process [ENTER]
Sep 05 00:22:23 corosync [corosy] persist_sync_finish enter
Sep 05 00:22:23 corosync [corosy] persist_sync_finish leave 1
Sep 05 00:22:23 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]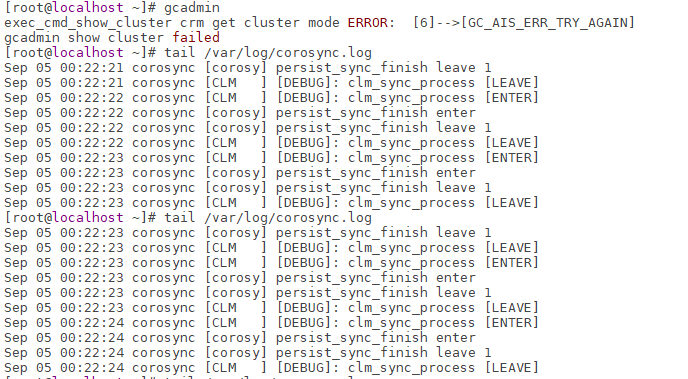
一直到出现如下日志时,才恢复正常日志输出:persist_sync_finish enter。证明新启动的节点,一直在从正常节点同步数据,等完成了就可以正常对外提供服务了。
Sep 05 00:22:48 corosync [corosy] persist_sync_finish enter
Sep 05 00:22:48 corosync [corosy] persist_sync_finish leave 1
Sep 05 00:22:48 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_process [ENTER]
Sep 05 00:22:49 corosync [corosy] persist_sync_finish enter
Sep 05 00:22:49 corosync [corosy] persist_sync_finish leave 1
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_process [ENTER]
Sep 05 00:22:49 corosync [corosy] persist_sync_finish enter
Sep 05 00:22:49 corosync [corosy] persist_sync_finish leave 1
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_process [ENTER]
Sep 05 00:22:49 corosync [corosy] persist_sync_finish enter
Sep 05 00:22:49 corosync [corosy] all node finish new cluster persist, sync process end
Sep 05 00:22:49 corosync [corosy] persist_sync_finish leave 0
Sep 05 00:22:49 corosync [CRM ] [INFO]: key_change_notify: cluster_state 2
Sep 05 00:22:49 corosync [LCK ] [INFO]: key_change_notify: cluster_state 2
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_lock begin
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_lock end
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_commit_takeover begin
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_commit_takeover end
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_commit begin
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_commit for offline node find out takeovernodeid = 1778515978
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_commit for conn disconnect find out takeovernodeid = 1778515978
Sep 05 00:22:49 corosync [LCK ] lck_remove_invalid_commit end
Sep 05 00:22:49 corosync [LCK ] qlm sync active remove lock 1 0
Sep 05 00:22:49 corosync [LCK ] qlm_sync_active_compatible_mode
Sep 05 00:22:49 corosync [LCK ] qlm_sync_active_compatible_mode name:, type:1 nodeid:1795293194
Sep 05 00:22:49 corosync [LCK ] lck_common_regist_sync_active regist_type:2,nodeid:1795293194,conn:(nil),trans:0
Sep 05 00:22:49 corosync [LCK ] lck_unregist_common_regist regist type not find,2
Sep 05 00:22:49 corosync [LCK ] lck_common_regist_sync_active regist_type:4,nodeid:1795293194,conn:(nil),trans:0
Sep 05 00:22:49 corosync [LCK ] masternodeid = 1778515978
Sep 05 00:22:49 corosync [LCK ] [INFO]: notify_cluster_state_change_to_consumer:state:2,local_conn:(nil),event_conn:(nil),node_id:1795293194
Sep 05 00:22:49 corosync [LCK ] [INFO]: lck_print_commit_takeover_list [ENTER]
Sep 05 00:22:49 corosync [LCK ] [INFO]: NodeId = 1778515978 connection:0xc41440
Sep 05 00:22:49 corosync [LCK ] [INFO]: lck_print_commit_takeover_list [END]
Sep 05 00:22:49 corosync [LCK ] [INFO]: lck_print_commit_list [ENTER]
Sep 05 00:22:49 corosync [LCK ] [INFO]: lck_print_commit_list [END]
Sep 05 00:22:49 corosync [LCK ] lck regist consumer:type:4,master_nodeid:1778515978,num:1
Sep 05 00:22:49 corosync [LCK ] lck regist consumer:nodeid:1778515978,info:
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_process [LEAVE]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_activate [ENTER]
Sep 05 00:22:49 corosync [LCK ] lck_sync_reset enter
Sep 05 00:22:49 corosync [LCK ] lck_sync_reset leave
Sep 05 00:22:49 corosync [CRM ] [DEBUG]: crm_sync_reset [LEAVE]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_reset [ENTER]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_activate [LEAVE]
Sep 05 00:22:49 corosync [CLM ] [DEBUG]: clm_sync_activate [LEAVE]
Sep 05 00:22:49 corosync [MAIN ] Completed service synchronization, ready to provide service.
Sep 05 00:22:49 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
Sep 05 00:22:49 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet masternodeid = 1778515978[LEAVE]
Sep 05 00:22:49 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
Sep 05 00:22:49 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet masternodeid = 1778515978[LEAVE]
Sep 05 00:22:54 corosync [CLM ] port scan read error ip:::ffff:10.0.2.107 port:5258 time:5000(ms) cfg_connect_timeout:5000(ms) error:11 Resource temporarily unavailable
Sep 05 00:22:54 corosync [CLM ] port scan read error ip:::ffff:10.0.2.107 port:5258 time:4999(ms) cfg_connect_timeout:5000(ms) error:11 Resource temporarily unavailable
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverRegist [ENTER]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverRegist [LEAVE]
Sep 05 00:22:54 corosync [LCK ] EXEC request: saLckRecoverRegist 1795293194
Sep 05 00:22:54 corosync [LCK ] EXEC notification: recover_regist_changed
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet masternodeid = 1778515978[LEAVE]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet masternodeid = 1778515978[LEAVE]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckCommitRegistTakeover [ENTER]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckCommitRegistTakeover [LEAVE]
Sep 05 00:22:54 corosync [LCK ] EXEC request: saLckCommitRegistTakeover 1795293194
Sep 05 00:22:54 corosync [LCK ] lck_add_takeover_list nodeid 1795293194
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet masternodeid = 1778515978[LEAVE]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverRegistInfoGet [ENTER]
Sep 05 00:22:54 corosync [LCK ] LIB request: gcLckRecoverRegistInfoGet [LEAVE]
Sep 05 00:22:57 corosync [LCK ] LIB request: gcLckCommonRegist type:4[ENTER]
Sep 05 00:22:57 corosync [LCK ] LIB request: gcLckCommonRegist type:4[LEAVE]
Sep 05 00:22:57 corosync [LCK ] EXEC request: saLckCommonRegist nodeid:1795293194,type:4
Sep 05 00:22:57 corosync [LCK ] type:4,masternodeid = 1778515978
Sep 05 00:22:57 corosync [CLM ] EXEC request: Invaild_Node_Del delete node: 1795293194
Sep 05 00:22:57 corosync [CLM ] EXEC request: notification_clusterstate_changed clusterstatechange = 1, trackflag = 4, num = 1
Sep 05 00:22:57 corosync [CLM ] nodeid = 1795293194
Sep 05 00:23:24 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
Sep 05 00:23:24 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet masternodeid = 1778515978[LEAVE]
Sep 05 00:23:24 corosync [LCK ] LIB request: gcLckRecoverRegistInfoGet [ENTER]
Sep 05 00:23:24 corosync [LCK ] LIB request: gcLckRecoverRegistInfoGet [LEAVE]
Sep 05 00:23:54 corosync [LCK ] LIB request: gcLckRecoverMasterNodeGet [ENTER]
总结
当节点离线时,gcware服务需要的数据将不再是最新的,当服务启动后,需要从其它节点同步数据,其耗时取决于期间其它节点做过的操作,一般看REDOLOG, 本地需要重做一次。