数据库为了高可用,在网络层可以采用bond方式避免网卡故障,连接多个交换机避免交换机单点故障。本文介绍一次因bond网络原因导致的加载,dml等都机器缓慢的性能问题。
目录导航
现象
客户反馈,现场加载机器缓慢。部分已经超过2小时尚未结束。日常只需要1分钟以内,大部分几秒即可完成。

排查过程
查看各节点iostat性能
首先怀疑部分节点有性能问题,用过iostat查看,所有节点都极其空闲。 cpu不超过30%,io不超过10%。
查看网卡ethtool
未发现网卡降速,都是万兆
查看各节点操作系统日志
/var/log/messages 未发现报错。
重启数据库服务
客户自行重启了整个集群的数据库服务,现象依旧。
测试数据源到集群节点的网络性能
从加载数据源,用scp复制1GB的文件到集群节点,每秒在50MB左右,未发现有明显性能问题。
查看trace日志
简单的insert select, 节点17行耗时1分多,发现第1个节点耗时长(Finish ACK)

怀疑这个节点的网络故障。
关闭第一个节点的服务
将数据库服务关掉,转到第二台服务器监控。发现性能略有提升但经常发生gcadmin 报集群LOCK。许多SQL都rollback,根本没法继续观察。
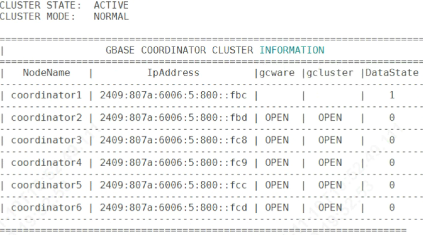
检查gcware服务日志
发现第二台服务器经常从管理节点里离线,导致服务重建导致。而其它节点则一直没问题。
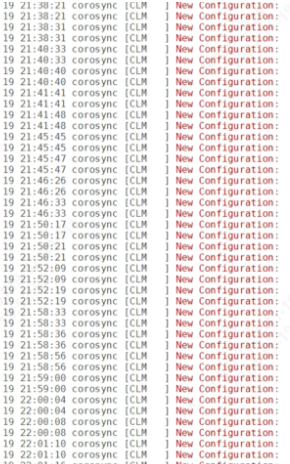
根据历史日志,第二个节点fbd故障记录远大于第一个节点fdc
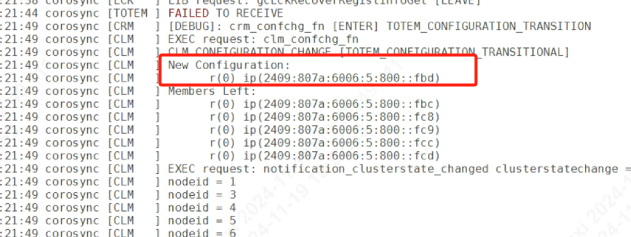
而节点离线的原因,是因为一直没有收到心跳导致,包括fbd没有收到其它节点心跳,其它节点也没有收到fbd的心跳。对比其它节点日志印证了这个现象。
以此判断,fbd网络故障比fdc更严重。 其与其它节点之间一定存在了网络阻塞。
现场bond情况
考虑到现场IP包含2个部分,fbX 和fcX, 是否存在跨交换机的情况。
客户反馈,现场初期就2个节点,后来扩容4个节点,用了新的交换机。 而每个节点都做了网卡绑定,且分别绑定到2台交换机避免单点故障。
而系统之前一直正常,考虑是否出现了网卡或交换机切换。
更改bond
将第二个节点的bond强行指定网卡1,重启服务,系统瞬间恢复了正常,且持续稳定。
BONDING OPTS="mode=1 miion=100 primary=eno1"怀疑第二个节点的交换机或网线,出现了阻塞或故障。
总结
bond本来是为了避免网络单点故障引入的,但现场前2个节点的备用交换机,与新的4个节点间有网络通讯故障(估计是udp包广播不通或大量拦截)。而这个网络切换是OS层发生的,应用层无法感知。 从而导致如果用的是第一个交换机,则一切正常,如果切换到了第二个,则会出现因网络导致的性能问题。
现场网卡做了bond,建议测试下切换后的性能。