GBase 8a MPP 集群,可以通过gcadmin命令查看每个节点的服务状态。正常情况下,应为OPEN。本文重点介绍gclusterd和gbased两个服务常见的几种会到导致服务为CLOSE的原因。
目录导航
例子
服务检测相关问题
GBase8a的服务检测有超时配置,默认5秒,如果超过了还没有正常返回,则判断服务故障CLOSE。
此类问题是服务本身没问题,是正常运行的,但由于网络,负载等相关的环境出现故障。导致检测服务异常。
防火墙
这个在初始安装,或者现场做过安全加固后最常见。
现象
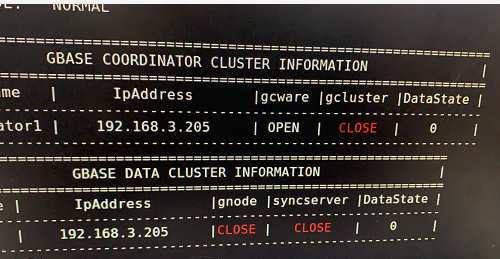
最常见的时互相看对方为CLOSE,而自己为OPEN.
比如A,B两个节点,在A节点看,自己是OPEN的,而B上服务都是CLOSE;而在B节点看,自己是OPEN,而A是CLOSE。
对于V8版本集群,一般伴随着集群状态为LOCK。
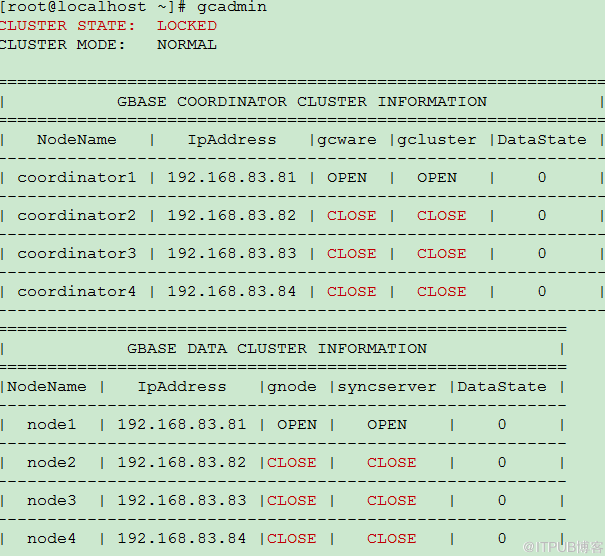
如果是V95集群,可能伴随着gcadmin命令长时间不返回现象。
解决方法:
查看防护墙/selinux是否关闭。
脑裂
常见于V8版本,V9未见过。
一般是corosync配置的节点数较多(20+)场景。所有管理节点同时启动服务时,有概率会发生。管理节点越多,几率越高。
当然网络如果偶发抖动,也可能产生这个现象,但概率极低。
现象
服务状态偶发的出现CLOSE, 但有时又能显示OPEN。
解决方法:
将带有corosync/gcware服务全部停止 stop,然后再逐台启动 start,不是重启restart。
网路差
网络设备问题,包括网卡,网线,交换机等。
现象:
服务状态也是时好时坏。但一般会持续很长时间。
ping或者scp传输数据性能差。
也出现过网卡,降速到10M或100M了。
gcware日志里,有cfg_connect_timeout报错字样。
解决方法
排查网络故障。
服务器负载高
服务器负载高,特别是磁盘,会导致在检测周期内没有及时响应,超时判断为CLOSE。
现象:
大部分是个别节点,或者一批类似的服务器。
常见于偶发CLOSE,其它时间是OPEN
查看机器资源,CPU/磁盘长时间100%,其中磁盘的await高于100ms. 如下是一个awai达到5秒以上的例子。
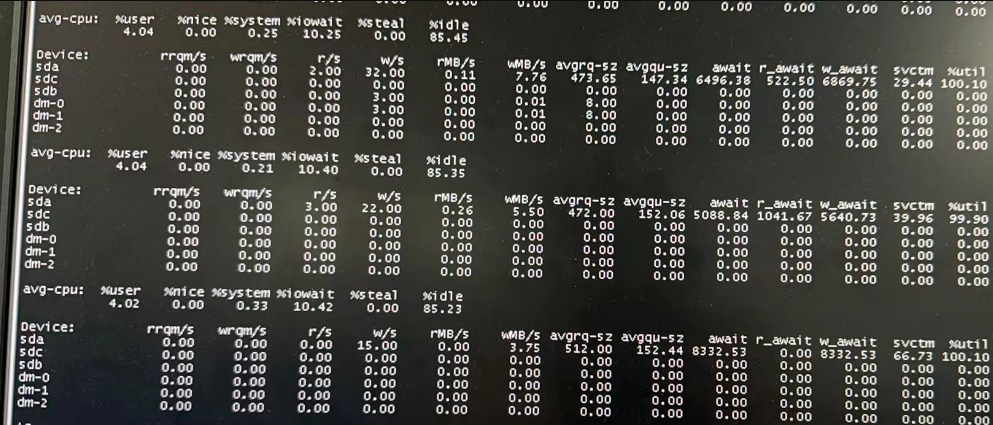
gcware日志里,有cfg_connect_timeout报错字样。
解决方法
排查负载高的原因。
可尝试reboot排除操作系统问题。
如果是磁盘问题,建议停服务后测试fio。
见过RAID卡没有内存,性能极差。
CPU降速。
服务干扰
其它机器,安装过数据库服务,但停用后,没有卸载干净,IP也变了。 一旦服务启动,会干扰现有IP的服务。
现象
服务时好时坏,但持续不断,间隔很短。
逐个管理节点运行tcpdump 会看到不输入集群IP的节点发来数据包。
参考:GBase 8a 集群服务corosync、gcware由于其它IP干扰导致异常
解决方案
找到干扰集群,卸载集群或者删除gcware配置文件。 比如86版本的 /etc/corosync/corosync.conf,95版本的安装目录/gcware/conf/gcware.conf
服务无法启动
这个就是服务本身出问题,无法启动。常见于系统做了变动,比如改了操作系统参数,数据库参数,本机环境出问题等。
一般服务多次restart, 甚至服务器reboot后,依然还无法恢复的,算服务无法正常启动了。
数据库参数问题
常见于参数不存在,参数值配置错误等。
现象:
数据库的system.log日志里,会给出不支持的参数或参数值的报错信息。
也可以手工执行gclusterd,看到错误信息。如下是一个参数值设置错误的例子。

常见于版本打过补丁。
解决方法
根据报错内容,修正参数。
数据库权限问题
数据库相关程序不能在777权限下,特别是config下的配置文件。
另外,所有可执行文件,必须有x可执行权限。
现象:
查看system.log会发现某些不符合要求的程序或文件。 而默认的配置,少了某些参数,可能导致服务无法启动。
手工运行gclusterd,会报permission deny。
解决方法
设置数据库配置文件640或600权限
查看可执行文件,增加x权限。
数据库运行用户问题
V95版本不能在操作系统用户root下运行,启动会报错。
现象
用操作系统root用户启动,发现服务一直无法正常运行。
手工执行gclusterd或者gbased报错,显示不能以root运行
解决方法
切换到dbaUser下启动服务。
数据库文件属主问题
所有数据库文件的属主必须是dbaUser, 但如果用户重建过dbaUser(删除用户,再建立用户,uid会变化),会导致原有的数据库文件的属主错误,导致无法访问
现象
数据库目录和文件,无法通过dbaUser访问。用root用户查看文件属主,一般会出现数字。
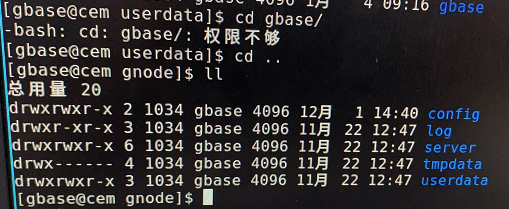
解决方案
通过chown -R 修改成正确的属主。
环境变量问题
环境变量一般放在dbauser下的.gbase_profile里,并通过.bash_profile调用。
如果环境变量被破坏,则可能导致服务运行的环境变量错误,导致服务无法启动。
常见于安全加固,或者安装了客户端且修改了环境变量的场景。
现象
查看.bash_profile文件和.gbase_profile,发现内容错误。比如目录不匹配。
解决方案
如果只是部分节点,可以从正常的节点复制一份。
如果全部损坏,可以从其它集群复制一份,然后按照本地目录做编辑调整。
PID文件问题
数据库启动后,会在log目录下生成pid文件,比如
/opt/gnode/log/gbase/gbased.pid该文件的内容,为进程号。比如gbased的进程1234, 则这个pid文件里保存的就是1234。
如果该文件已经存在,且对应的进程(/proc/1234)也存在,则表示已经有一个进程运行中。
现象
手工运行gbased时,报错 have another program is running
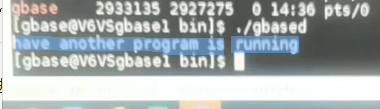
运行strace gbased可以看到检测过程
- 1、查看pid文件是否存在,如不存在,则正常继续了
- 2、如已存在,则打开文件,读取文件内容。如下图中为2363
- 3、检查/proc/2363是否已经存在,如已在,则表示已经有进程在运行中。
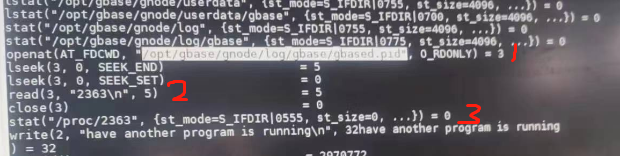
查看/proc/2363,确实已经存在了
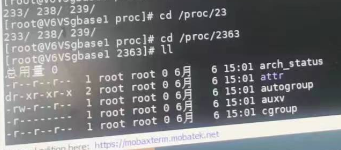
解决方法
删除pid文件即可。
数据文件损坏
由于系统宕机,断电,磁盘空间满等,导致数据文件没有正确的写入内容。在启动时,没有考虑到某些异常情况,导致启动失败。
常见于:
1、RAID没有电池的物理机,虚拟机,云主机等断电;
2、磁盘空间满且维持很长一段时间(分钟以上),数据库默认的守护进程gcmonit在发现进程(主要是gcware/corosync)消失后,只会自动拉起有限次数(默认10次,可修改gcmonit.conf调整参数),如果都没有成功,即使后面空间释放了,进程也不会自动拉起来。
总结
一个稳定运行的环境,出现服务CLOSE问题,多见于环境变动。根据服务是否真的无法启动,来分别处理。