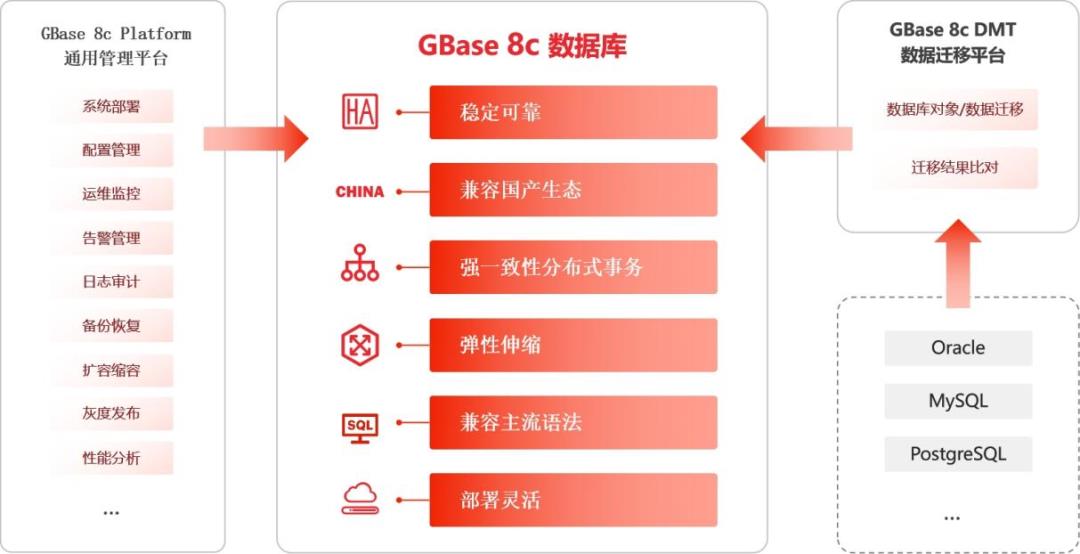
随着互联网时代的发展,联网业务高峰期间可能实时面临高并发的访问量。飞速增长的业务需求使得数据库计算和存储压力急剧增大,负载峰值不断攀升,将严重影响业务系统的正常访问。为了解决此类问题,南大通用GBase 8c多模多态分布式数据库增强了其在线扩容/缩容的能力。
目录导航
在线扩容 / 缩容
GBase 8c因其优秀的在线扩容/缩容能力,能够全面覆盖用户流量低高峰期的业务场景。用户根据业务需求、策略等设置伸缩规则。在业务需求增长时,系统自动增加数据库节点以保证计算存储能力;在业务需求下降时,系统自动减少数据库节点以节约成本。
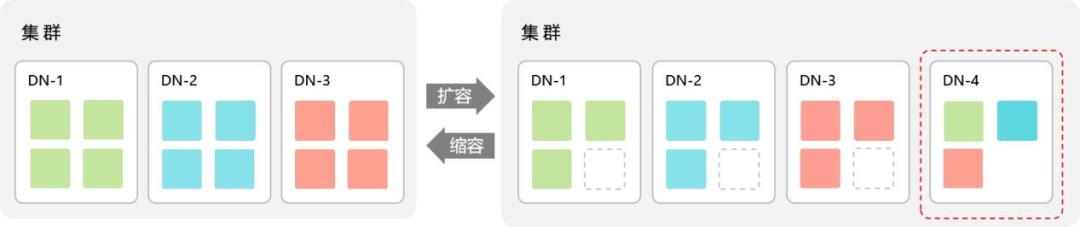
按照流程方式划分,GBase 8c在线扩容/缩容可分为普通表、Hashbucket表两种。默认创建普通表。普通表适合数据量小、数据文件有序的场景;Hashbucket表适合数据量大、数据文件繁杂、高并发的场景,在此类场景下,Hashbucket表的扩容缩容和查询性能更优越。
以下分别简述普通表和Hashbucket表在线扩容的原理。
普通表在线扩容原理
GBase 8c仅在数据重分布阶段中表切换操作时,出现秒级或毫秒级的短暂下线。扩容其余时间内均支持业务在线。存储节点扩容主要分为集群加节点、数据重分布两个阶段。
1. 集群加节点阶段。此阶段主要完成新节点的安装、元数据同步、启动等操作。
首先将新节点初始化并加到集群中,然后将老节点的元数据信息都同步到新节点中,为后续数据重分布阶段做准备。在元数据同步后启动、运行新节点,并切换Installation Group为新建的Node Group。
2. 数据重分布阶段。此阶段主要完成存储节点扩容后数据的重分布,以及切换元数据。
首先在数据重分布之前,进行检查新旧Node Group、创建临时表和delete_delta表等准备工作。然后采用自研Hash数据分布算法,完成基线数据重分布操作,并追增扩容期间产生的业务数据,完成增量数据重分布。在最后一轮数据追增完成后,关闭数据追增模式,并完成表切换、删除临时列、更新Node Group等收尾操作。
HashBucket表在线扩容原理
此外,GBase 8c还支持创建HashBucket表。创建命令如下:
CREATE TABLE tab_name(rel_name rel_type) with(segment=on,bashbucket=on);HashBucket表使用段页式存储方式,以解决数据文件多的问题。
每一个bucketid一段连续存储,相同的bucketid存储在相同文件。因此在线扩容/缩容进行数据搬迁时,仅需搬迁发生变化的bucketid对应的块文件。在表切换、交换物理文件时,仅需在存储结构进行修改。从而,数据搬迁量大大减少。
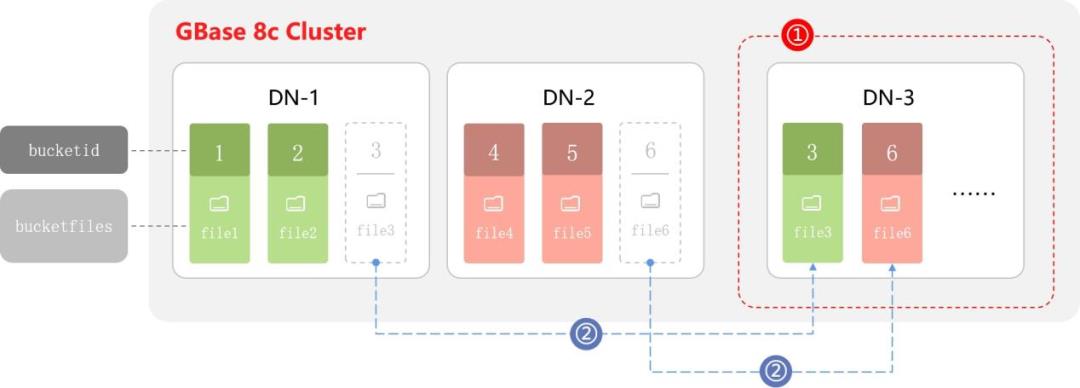
Hashbucket表扩容数据流图如上所示。例如,扩容前,bucketid为1、2、3的数据存放在DN1节点,bucketid为4、5、6的数据存放在DN2节点。
扩容时,如果新节点不在原集群中,则需将新增的DN3加到集群中(如图步骤①所示)。根据数据分布算法生成的新map,仅将bucketid为3、6的数据由老节点搬迁至新增的DN3节点(如图步骤②所示),其他bucketid值的数据无需搬迁。由此看出,数据搬迁时只需移动发生变化的bucketid对应的数据,而非所有节点的数据重分布,减少扩容过程中的搬迁数据量,有效提高了扩容速率。
关于 GBase 8c
GBase 8c是基于openGauss3.0构建的一款多模多态的分布式数据库,支持行存、列存、内存等多种存储模式和单机、主备式、分布式等多种部署形态。GBase 8c具备高性能、高可用、弹性伸缩、高安全性等特性,可以部署在物理机、虚拟机、容器、私有云和公有云,为关键行业核心系统、互联网业务系统和政企业务系统提供安全、稳定、可靠的数据存储和管理服务。